
- 분류 전체보기 (141)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- virtualization
- spring batch
- Container
- spring boot
- 가상화
- spring cloud
- 자바
- 스프링
- Spring Security
- Java
- 백엔드
- vm
- web server
- JPA
- Spring
- 데이터베이스
- 배포
- 영속성 컨텍스트
- CI/CD
- computer science
- 컨테이너
- mysql
- CS
- 스프링 부트
- 웹 서버
- 스프링 배치
- HTTP
- 도커
- 스프링 시큐리티
- ORM
- Today
- Total
개발 일기
[Java] JDBC(Java DB Connectivity) & HikariCP(Hikari Connection Pool) 본문
[Java] JDBC(Java DB Connectivity) & HikariCP(Hikari Connection Pool)
개발 일기장 주인 2024. 9. 21. 17:33
JDBC(Java Database Connectivity)란?
JDBC(Java Database Connectivity)는 Java에서 데이터베이스에 접속할 수 있도록 하는 Java 표준 API이다.
즉, JDBC API를 통해 자바 코드로 데이터베이스를 연결할 수 있고, SQL 쿼리문을 보내서 쿼리를 실행하며 결과 값을 받아올 수 있다.
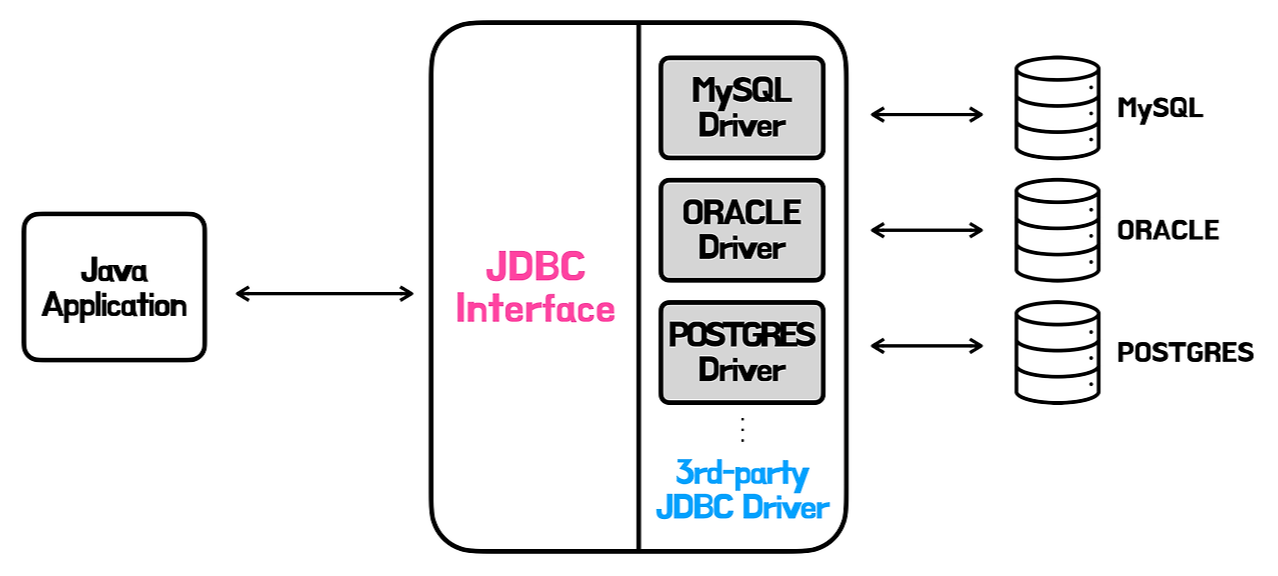
JDBC는 Java 애플리케이션 내에서 JDBC API를 사용하여 데이터베이스에 접근하는 단순한 구조이다.
JDBC를 통한 DB 연동 흐름


1. 드라이버 로딩
- JDBC 드라이버를 사용하여 Java 애플리케이션이 데이터베이스와 통신할 수 있도록 하는 첫 번째 단계.
- DriverManager 클래스는 JDBC 드라이버를 관리하는 역할을 한다.
- 그러나 JDBC 4.0부터는 드라이버가 자동으로 로드되므로 명시적으로 로드할 필요X.
- 대신, JDBC URL에 따라 DriverManager가 적절한 드라이버를 찾습니다
Class.forName("com.mysql.cj.jdbc.Driver"); // 명시적으로 드라이버 지정
2. Connection 객체 생성
- 드라이버가 로드되면 DriverManager.getConnection() 메서드를 사용하여 데이터베이스와의 연결을 설정
- 이 메서드는 JDBC URL, 데이터베이스 사용자 이름, 비밀번호 등을 인자로 받는다.
Connection connection = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/db", "username", "password");
3. Statement 객체 생성
- 데이터베이스에 쿼리를 실행하려면 Statement 객체를 사용해야 한다.
- Connection 객체의 createStatement() 메서드를 호출하여 생성
Statement statement = connection.createStatement();
4. SQL 쿼리 실행 및 ResultSet 처리
- Statement 객체를 사용하여 SQL 쿼리를 실행하고 그 결과를 ResultSet 객체로 받는다.
- ResultSet 객체는 SQL 쿼리 결과를 테이블 형식으로 저장하고, 데이터를 순차적으로 읽을 수 있게 해준다.
// 조회 쿼리
ResultSet resultSet = statement.executeQuery("SELECT * FROM users");
while (resultSet.next()) { // Cursor를 사용하여 행을 순차적으로 탐색
System.out.println(resultSet.getString("username"));
}
// insert, update, delete
String sql = "INSERT INTO users (username, email) VALUES ('johndoe', 'johndoe@example.com')";
int rowsAffected = statement.executeUpdate(sql); // 영향받은 행의 수 반환
5. 리소스 정리 (닫기)
- JDBC는 네트워크와 시스템 리소스를 사용하므로, 사용이 끝난 후에는 반드시 연결을 닫아줘야 한다.
- 자원을 닫을 때는 열었던 순서의 반대로 닫는다.
ResultSet → Statement → Connection
resultSet.close(); // ResultSet 닫기
statement.close(); // Statement 닫기
connection.close(); // Connection 닫기
커넥션 풀(Connection Pool) - DBCP

- 커넥션을 생성하기 위해서는 매번 사용자가 요청을 할 때마다 드라이버를 로드하고 커넥션 객체를 생성하여 연결하고 종료해줘야한다.
- 커넥션을 새로 생성하고 닫는 작업은 TCP/IP Connection(3-way handshake 등 네트워크 작업), 인증 등의 과정을 포함하므로, 이 과정이 반복되면 성능 저하가 발생할 수 있습니다.
- 즉, 커넥션을 반복적으로 생성하고 파괴하는 작업은 성능에 부담이다. (매 요청마다 이 과정을 반복하면 그만큼 지연 발생, 자원 소모)
➜ 이러한 문제를 해결하기 위해 애플리케이션 로딩 시점에 Connection 객체를 미리 생성하고, 애플리케이션에서 데이터베이스에 연결이 필요할 경우 미리 준비된 Connection객체를 사용하여 애플리케이션의 성능을 향상하는 커넥션 풀(Connection Pool)이 등장
사실 시스템 상황마다 다르지만 MySQL 계열은 수 ms(밀리초) 정도로 매우 빨리 커넥션을 확보할 수 있다.
반면에 수십 밀리초 이상 걸리는 데이터베이스들도 있기 때문에 커넥션 풀이 필요하다.

HikariCP

Spring Boot 2.0 이전 버전에서는 Apache 재단의 오픈 소스인 Apache Commons DBCP를 주로 사용하였지만, 스프링 부트 2.0 이후 HikariCP를 기본 DBCP로 채택하여 사용되고 있다.
가벼운 용량과 빠른 속도를 가지는 우수한 성능의 JDBC Connection Pool Framework이다.

커넥션 풀 동작 과정
유휴 커넥션 존재 시

- 어떤 쓰레드가 커넥션을 요청하면, 먼저 풀에 유휴(사용하지 않는) 커넥션이 있는지 확인.
- 유휴 커넥션이 있다면, 그 커넥션을 쓰레드에게 반환한다.
- 이 커넥션을 통해 데이터베이스에 작업 수행.
유휴 커넥션이 없는 경우

- 만약 유휴 커넥션이 없다면, 쓰레드는 HandOffQueue라는 대기열에 들어간다. 이 대기열은 다른 스레드가 커넥션을 반납할 때까지 기다리는 곳이다.
- 대기 중인 쓰레드는 주기적으로 HandOffQueue를 확인하면서 다른 스레드가 커넥션을 반환하기를 기다린다.
- 다른 쓰레드가 작업을 마치고 커넥션을 반납하면, 커넥션 풀은 그 커넥션을 HandOffQueue에 추가한다.
- 대기 중인 스레드 중 하나가 HandOffQueue에 추가된 커넥션을 발견하면, 해당 커넥션을 획득하고 데이터베이스 작업을 시작.
만약 커넥션 풀의 크기가 너무 작다면?
커넥션을 요청한 쓰레드가 많고, 유휴 커넥션이 부족하면 많은 쓰레드가 HandOffQueue에서 대기하게 된다.
대기 중인 스레드가 많아질수록 시스템의 응답 속도가 느려지거나 지연이 발생할 것이다.
➜ 커넥션 풀의 크기를 늘려주면 해결될텐데, 그렇다면 적절한 커넥션 풀의 크기는?
적절한 커넥션 풀의 크기
크면 클 수록 좋다고 생각될 수도 있지만 Connection을 사용하는 주체인 Thread의 수보다 커넥션 풀의 크기가 크다면 사용되지 않고
남는 커넥션이 발생하기 때문에 사용되지 않는 커넥션이 생겨 메모리 낭비가 발생할 것이다.
하나의 CPU 코어가 있는 컴퓨터도 수십 혹은 수백 개의 스레드를 동시에 지원할 수 있다. 하지만 이것은 운영체제의 속임수일 뿐이다. 실제로 단일 코어는 한 번에 하나의 스레드만 실행할 수 있다. 운영체제는 컨텍스트 스위칭을 한 뒤 다른 스레드의 코드를 실행할 뿐이다. 즉 빠른 시간의 컨텍스트 스위칭으로 동시에 진행하는 것 처럼 보일 뿐이다.
단일 CPU가 주어지면 A와 B를 순차적으로 실행하는 것이 시분할을 통해 A와 B를 동시에 실행하는 것 보다 항상 빠를 것이라는 것은 컴퓨팅의 기본 법칙이다. 스레드 수가 CPU 코어 수를 초과하면 단순히 스레드 수가 더 많아질 뿐이지 더 빠른 속도를 보장하는 것은 아니다. 즉 단순히 풀의 크기를 늘린다고 더 빠른 속도로 처리되는 것은 아니다.

그러나 디스크와 네트워크가 변수로 작용하게 된다. 데이터베이스는 일반적으로 디스크에 저장하는데, 전통적인 모터 구동 암에 읽기/쓰기 헤드가 장착된 회전 금속 플레이트로 구성된다. 읽기/쓰기 헤드는 한 번에 한 곳에만 읽을 수 있으며 다른 쿼리에 대한 데이터를 읽기 위해서는 새 위치를 검색 해야 한다. 따라서 탐색 시간 비용과 플래터의 데이터가 다시 돌아오기 까지 디스크를 기다려야 하는 회전 비용이 추가적으로 발생한다.
디스크에서 위 과정이 일어나는 동안 스레드는 block 된다. 이 시간 동안 다른 스레드의 작업을 처리할 수 있는 여유가 생기게 된다. 이러한 여유 덕분에 실제로 더 많은 작업을 수행할 수 있게 된다.
네트워크도 디스크와 유사하다. 이더넷 인터페이스를 통해 유선으로 데이터를 작성하면 송/수신 버퍼가 가득차거나 멈출 때 block이 발생할 수 있다.

다양한 상황을 고려 했을 때 PostgreSQL에서는 아래와 같은 공식을 제안했다. 또한 여러 데이터베이스에도 적용할 수 있다고 언급되어 있다.
connections = (corecount * 2) + effectivespindle_count
- core_count * 2
: 코어 수에 근접할 수록 좋지만, 위에서 언급한 디스크 및 네트워크와 CPU의 속도차이로 인한 여유 시간을 활용하기 위해 계수 2를 곱해준다. - effective_spindle_count
: 하드 디스크는 하나의 spindle을 가진다. spindle은 데이터베이스 서버가 관리할 수 있는 동시 I/O 요청 수를 말한다. 디스크가 n개 존재하면 spindle_count는 n이 될 수 있다.
하나의 하드 디스크가 있는 4-core i7 CPU를 가진 서버에서 9 = (4 * 2) + 1의 커넥션 풀을 설정해야 한다. 대략 10을 설정할 수 있다. 위 공식은 절대적인 것이 아니기 때문에 풀 크기를 선정할 때 기준으로 활용할 수 있다.
사용자가 10,000명이라고 커넥션 풀이 10,000개를 설정한 것은 굉장한 낭비에 가깝다. 1,000개도 많다. 심지어 100개의 커넥션도 과하다. 위에 언급한 바와 같이 CPU core * 2 보다 훨씬 많은 경우는 거의 없다.
추가적으로, MySQL의 공식레퍼런스에서는 600여 명의 유저를 대응하는데 15~20개의 커넥션 풀만으로도 충분하다고 한다.
'Back-End > Java' 카테고리의 다른 글
| [Java] 시간 복잡도 (Time Complexity) - Big-O Notation (0) | 2024.10.22 |
|---|---|
| [Java] 자바 기본적인 입출력 방법 비교(Scanner와 BufferedReader 그리고 BufferedWriter) (1) | 2024.10.21 |
| [Java] 자바 접근 제어자(Access Modifier) 정리 - public/private/protected/default (0) | 2024.06.04 |
| [Java] 로그(Log)/로깅(Logging) 그리고 Java 로깅 프레임워크들 (0) | 2024.05.22 |
| [Java] JIT 컴파일러(Just-in-Time Compiler)란? - 컴파일러와 인터프리터의 비교 (2) | 2024.03.06 |



