
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- Spring
- 배포
- spring boot
- Redis
- 가상화
- 자바
- mysql
- computer science
- 컨테이너
- Hackathon
- 스프링 부트
- CS
- Container
- JPA
- 스프링 시큐리티
- Spring Security
- Java
- 데이터베이스
- 영속성 컨텍스트
- 도커
- virtualization
- spring cloud
- 스프링 배치
- 스프링
- CI/CD
- 백엔드
- 웹 서버
- vm
- 해커톤
- ORM
- Today
- Total
개발 일기
[Redis] Redis 뜯어보기 1 - 내부 구조 및 동작 방식(feat. I/O-Multiplexing) 본문
[Redis] Redis 뜯어보기 1 - 내부 구조 및 동작 방식(feat. I/O-Multiplexing)
개발 일기장 주인 2025. 8. 11. 02:45https://ai-back-end.tistory.com/98
[Redis] Redis(Remote Dictionary Server) 이해하고 사용하기
OAuth2.0+JWT에서 Refresh Token을 백엔드 단에서 소유하고 있기 위해 Redis에 저장했다. 그냥 다들 그렇게하니까 그렇게 처리해봤는데 정확히 알고 쓴다는 느낌이 없어서 이번 기회에 Redis에 대해 이해
ai-back-end.tistory.com
작년 9월에 한 번 Redis에 대해 공부했지만, 이제는 Redis와 더 친숙해졌고 어떨때 사용되는지 더 와닿고 있는데, 그래서 이번에는 단순한 사용법이 아니라 내부 동작 원리까지 깊게 이해하고자 합니다.
최근 SLASH 23 - 실시간 시세 데이터 안전하고 빠르게 처리하기 영상을 보았는데, 발표자분은 낮은 지연 시간과 빠른 장애 복구가 핵심인 시세 플랫폼에서 다음과 같은 구조를 설계했다고 합니다.
수신부에서는 한국거래소(KRX)에서 제공하는 시세 데이터를 UDP 멀티캐스트 그룹을 통해 받아오고, 이를 처리부로 전달하는 과정에서 UDP 멀티캐스트, Kafka, Redis Pub/Sub 등의 후보 기술을 검토했습니다. 최종적으로는 지연율이 가장 낮았던 Redis Pub/Sub을 선택했는데, 특히 인상 깊었던 점은 단순히 Redis Pub/Sub을 “지연율이 낮다”에서 끝이아니라, 내부적으로 어떻게 동작하는지, 그리고 그 구조에서 지연 시간이 낮게 나오는 이유까지 깊게 이해하고 사용했다는 점입니다.
저도 이번에는 Redis를 단순히 “사용할 줄 아는 도구”로만 그치지 않고,
100% 이해하는 데에는 한계가 있겠지만 최대한 왜 이런 동작 플로우가 나오는지, 내부 메커니즘이 무엇인지 등 추가적으로 궁금했던 것들을 깊게 파고들어 보고자 합니다.
Redis 내부 구조 및 동작 방식
Redis는 기본적으로 Single Thread인줄 알고 있었는데 몇몇 블로그 를 보면 또 Multi Thread라는 말이 있다.
Redis는 원래 단일 스레드로 네트워크 입출력(I/O)과 명령 처리(Command Execution)을 모두 수행했으나, 네트워크에서 많은 클라이언트 요청이 들어오면, 입출력 작업이 지연을 발생시켰다.
# 기존 싱글 스레드 I/O
[메인 스레드]
1. 소켓에서 데이터 읽기
2. 명령 파싱
3. 명령 실행
4. 응답 작성 및 전송
(다음 클라이언트 반복)
# Threaded I/O
[메인 스레드] epoll/kqueue로 이벤트 감시
│
├─ 읽기 가능: 소켓에서 데이터 읽기(옵션에 따라 멀티스레드 가능)
│ └─ 읽은 요청을 메인 스레드가 파싱 + 명령 실행
│
└─ 쓰기 가능: 응답 데이터를 워커 스레드들에게 분배
└─ 워커 스레드들이 병렬로 socket.write() 호출그런데 Redis 6.0 이후 도입된 Threaded I/O를 통해 I/O 작업을 멀티 스레드로 처리해 더 빨리 읽고 쓰도록 개선
Redis를 쓰는 사람들은 Redis에 가졌던 많은 불만 중에 하나가 왜 Multi Thread를 지원하지 않는가였으며 하지만 한편으로는 Multi Thread를 지원하면 기존의 Redis의 특징중에 하나였던 Atomic을 어떻게 보장할 것인가도 의문이였다.
Threaded I/O?
Single thread가 아닌데 redis의 장점이였던 Atomic을 어떻게 보장하지?라는 의문이 들 수 있다.
하지만 걱정할 필요 없다! redis는 Single thread이기 때문이다.
이게 무슨 말이냐면 redis는 부분적으로 Single thread와 Multi Thread를 함께 사용한다.
네트워크 입출력 처리(읽기, 쓰기)를 별도의 멀티 스레드들이 담당하게 하여, 메인 이벤트 루프(단일 스레드)가 명령 처리에만 집중하도록 만든 것이다.
클라이언트로 부터 전송된 명령(네트워크)를 읽는 부분과 전송하는 부분은 Multi Thread로 구현되어있으며
우리가 redis에 요청한 명령을 실행(처리)하는 부분은 Single thread로 구현되어 있다.
따라서, single thread의 장점인 Atomic한 요청 처리가 가능한 것이다.
Threaded I/O를 켜면?
- 메인 스레드 → 클라이언트 요청 파싱, 명령 실행
- 워커 스레드(여러 개) → 소켓 읽기/쓰기 작업 병렬 처리
아래 그림을 통해 더 구체적으로 알아보자.
그 전에 Blocking I/O, Non-Blocking I/O, I/O Multiplexing에 대해 기본적으로 알아야 이해가 될 것같아 해당 내용은 별도로 블로그를 작성하겠다.
그 전에 I/O Multiplexing 살펴보기..
I/O 멀티플렉싱은 하나(최소한)의 스레드에서 다수의 클라이언트에 연결된 소켓(파일 디스크립터-FD)을 동시에 관리/감시하면서 소켓에 이벤트(read/write)가 발생할 때만 해당 이벤트를 처리하도록 구현함으로써 어느 FD에서 읽기나 쓰기 같은 이벤트가 발생했는지 효율적으로 알아내는 것.

- 그리고 멀티플렉싱 모델에서는 select 함수를 사용한다. 해당 함수를 호출해서 여러 개의 소켓 파일 중 read 함수로 데이터 호출이 가능한 소켓이 생길 때까지 대기한다.
- select 함수 결과 값으로 read 함수를 호출할 수 있는 소켓의 목록이 반환되면 이제 다시 read 함수를 통해 해당 데이터들을 유저 공간으로 복사해 온다.
I/O 멀티플렉싱은 하나의 스레드로 처리할 수 있다는 것이 아주 큰 장점이다.
그리고 전통적으로 이것은 select 또는 poll 시스템 콜로 수행된다.
그러나 해당 시스템 콜은 수 천개의 커넥션이 생성되었을 때 모든 파일을 스캔해야 하므로 O(n)으로 성능이 별로 좋지 않다.
그래서 Linux에서 epoll()이나 FreeBSD의 kqueue()를 사용하면 O(1) 상수 시간으로 전체 파일 셋이 아닌 변경 사항이 있는 파일만 던져주므로 성능이 좋다.

Redis는 Solaris 10의 evport, Linux의 epoll 및 Mac OS/FreeBSD의 kqueue를 포함하여 시간 복잡도가 O(1)인 I/O 멀티플렉싱 기능을 기본 구현으로 우선적으로 선택.

select() ➜ poll() ➜ epoll(), kqueue()
┌─────────────┐
│ User Space │
└──────┬──────┘
│ FD 목록 전달 (select: 비트마스크 / poll: 배열)
▼
┌─────────────┐
│ Kernel Space│
│ - 이벤트 감시 │
│ - 타이머 확인 │
└──────┬──────┘
│
▼
FD 상태 변화를 User Space로 반환
(select: 수정된 비트마스크 / poll: revents 플래그)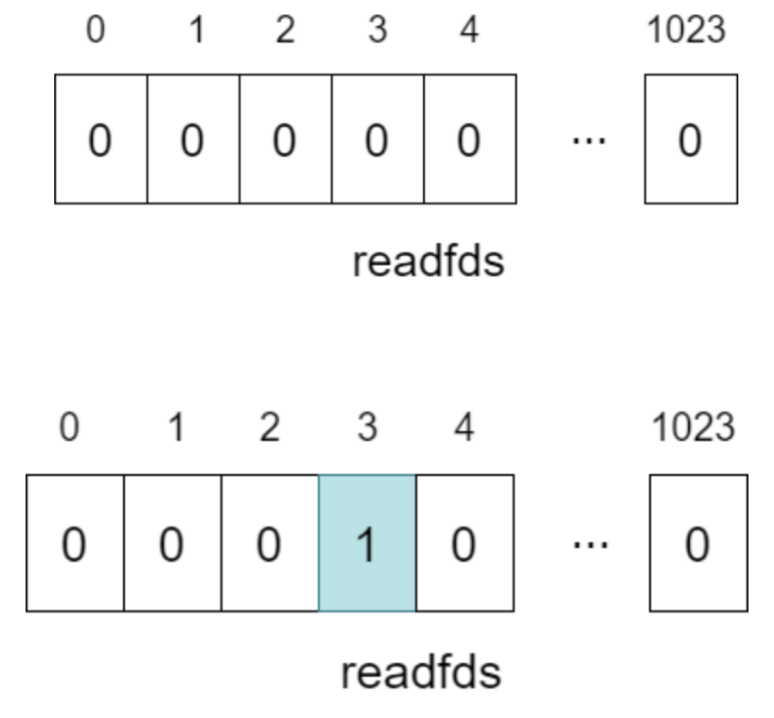
- select()
- 유저 공간에서 fd_set에 매번 전체 fd들을 담아 select() 호출하여 fd_set을 커널 영역으로 복사하며, 커널은 이 fd 집합 전체를 확인해서 준비된 fd들만 표시해 반환.
- fd_set 구조체는 1024 크기를 가지는 비트마스크 배열을 포함하는데, 파일 지정 번호는 각 비트 배열 첨자에 대응하는 구조를 가지고 있다. 예를 들어 파일 지정번호가 3이면 4번째 비트 배열에 대응된다.
또한, 해당 구조체는 읽기/쓰기/예외 세트로 나뉘어 진다. - 위 그림1과 같이 만약 변경된 데이터가 있으면 해당 비트값이 1로 설정되고, 이 비트 값을 검사함으로써 어떤 파일 지정 번호에 변경된 데이터가 있는지 확인해서 읽기/쓰기를 하면 된다.
- BUT, fd길이에 제한, fd를 하나하나 체크해야하기 때문에 fd 수 증가할 수록 On의 계산량도 증가하며
- 사용자가 selector.selectedKeys()를 호출하면 운영 체제는 모든 소켓을 검색하여 커널에서 유저 영역으로 복사한다. 연결 수(소켓 수)가 증가하면 순회 및 복제 시간이 선형 적으로 증가하고 메모리 소비가 증가한다.
- poll()
- struct pollfd 구조체(배열, 리스트) 사용 → events 필드로 읽기/쓰기 동시 지정 가능
- select와 달리 fd 수 제한(FD_SETSIZE) 없음
- 그럼 poll은 fd에 해당 events가 발생하는지를 검사하게 되고, 해당 events가 발생하면 revents를 채워서 돌려주게 된다. revents는 events가 발생했을 때 커널에서 이 events에 어떻게 반응했는지에 대한 반응값이다.
struct pollfd
{
int fd; // 관심있어하는 파일지시자
short events; // 발생된 이벤트
short revents; // 돌려받은 이벤트
}; - 하지만 여전히 호출할 때마다 배열(리스트) 전체를 커널로 전달(복사)하고, 커널은 배열을 스캔하므로 O(N).
- 그러므로 revent를 검사함으로써, 해당 fd에 읽을 데이터가 있다는 것을 알 수 있게 된다.
- epoll()
- select의 단점을 극복하기 위해 커널 레벨의 멀티플렉싱을 지원
- fd에 대한 루프를 돌지 않고, epoll_wait함수를 호출하면 관찰 대상fd들의 정보를 매번 전달할 필요가 없다.
- FD(파일 디스크립터)를 감시 목록에 등록하면, 커널이 내부적으로 Red-Black Tree + Ready List를 관리하며 이벤트 발생 시 Ready List에 해당 fd를 등록해 둔다.
- 커널 영역에 epoll_create를 통해 epoll 구조체(인스턴스)를 생성하고 epoll_ctl을 통해서 디스크립터를 등록,수정 그리고 삭제하고, epoll_wait를 통해 이벤트가 발생한 FD가 추가된 Ready List를 반환한다.
- kqueue()
- BSD 계열에서는 소켓뿐만 아니라 파일, 프로세스, 타이머, 시그널 등 다양한 자원 감시 가능
- FD 뿐 아니라 "이벤트 필터" 기반 구조로 확장성 높음.
- kqueue() → 커널에 kqueue 인스턴스 생성
- kevent(ADD) → 감시 대상과 이벤트 필터 등록 (예: EVFILT_READ, EVFILT_WRITE)
- 커널이 이벤트 발생 여부 체크
- 이벤트 발생 시 kevent 호출에서 즉시 반환
(1) epoll 구조
┌──────────┐ ┌──────────┐
│User Space│ │Kernel │
│ │ │ │
│epoll_ctl │───────▶│R-B Tree │
│ │ │ │
│epoll_wait│───────▶│Ready List│
└──────────┘ └──────────┘
│ 이벤트 발생 시 즉시 반환
(2) kqueue 구조
┌──────────┐ ┌────────────────┐
│User Space│ │Kernel │
│ │ │ │
│ kevent │───────▶│Event Filters │
│ │ │ (read/write, │
│ │ │ proc, timer) │
│ │ └──────┬─────────┘
│ │ ▼
│ │ [Ready List]
└──────────┘ │
▼
kevent 반환

전체적인 그림을 보면 Node.js의 동작 원리와 상당히 유사하다고 생각했다. 뜯어보니 실제로 그러한 것 같다.
각 클라이언트와 Redis 서버는 운영체제 내에서 각각 고유한 포트를 할당받아 소켓을 생성한다.
클라이언트 그룹인 A, B, C는 거의 동시에 Redis 서버의 IP와 포트로 연결 요청을 보내고, 이 연결 요청은 Redis 서버의 서버 소켓에서 수락된다. 이후 클라이언트들은 생성한 클라이언트 소켓을 통해 Redis 서버(서버 소켓)와 명령어를 주고받게 된다.
Redis는 기본적으로 단일 스레드 기반의 이벤트 루프 구조를 사용하지만, I/O 멀티플렉싱 단계에서는 운영체제 수준에서 멀티 스레드를 활용하여 다수의 클라이언트 소켓 입출력 상태를 감시한다. Linux의 epoll, BSD/macOS의 kqueue, Windows의 IOCP 등 고성능 I/O 멀티플렉싱 메커니즘을 통해, OS 커널이 여러 스레드를 활용해 소켓 입출력 이벤트를 효율적으로 감지한다.
이벤트 루프는 Task Queue에 등록된 작업 중 블로킹 작업등을 백그라운드 스레드(Worker Thread)에 위임한다.
작업이 완료되면 그 결과는 이벤트 루프에 반환되고, 이벤트 루프는 등록된 콜백 함수를 실행하여 최종적으로 클라이언트에 응답을 전송한다.
운영체제 레벨에서의 소켓 통신 동작 방식
[1]
클라이언트 A가 write() 호출 클라이언트 애플리케이션이 write() 같은 시스템 콜을 호출하면, 데이터는 유저 공간 → 커널 공간으로 복사된다.
클라이언트 프로세스 입장에서 “소켓에 쓴다”라는 건, 실제로는 FD 테이블을 통해 커널이 관리하는 소켓 송신 버퍼(send buffer)에 데이터를 넣는 것과 같습니다.
[2]
커널이 네트워크 전송 처리 커널 네트워크 스택이 TCP 프로토콜 처리를 거쳐 데이터를 패킷 단위로 만들고, 네트워크 인터페이스 카드(NIC)에 전달한다.
이 과정은 클라이언트 프로세스가 직접 패킷을 전송하는 게 아니라, 커널이 전송을 수행한다.
따라서 "클라이언트가 자기 소켓에만 쓰고 서버가 읽어가는" 게 아니라, 시스템 콜 순간 커널이 네트워크로 전송까지 책임진다.
[3]
서버(예: Redis)가 수신 Redis 서버 쪽 커널이 TCP 패킷을 수신하면 서버 소켓의 수신 버퍼(receive buffer)에 데이터를 저장한다. Redis 프로세스는 read() 또는 이벤트 루프에서 해당 소켓이 읽기 가능 상태(readable)임을 감지하면, 커널에서 유저 공간으로 데이터를 읽어간다.
Pipelining이 없어도 threaded I/O가 있다면 !
결과적으로 명령을 실행하는 부분이 단일 스레드로 처리되기 때문에, 처음에는 성능에 제한이 있을 것 같다는 의문이 들 수 있었지만,
Redis는 클라이언트가 여러 네트워크 패킷(명령)을 보내더라도 각 요청의 응답을 기다리지 않고 일괄 처리(batch processing) 하는 방식을 사용한다.
이렇게 하면 네트워크 오버헤드를 크게 줄이면서 전체 시스템 처리량을 높일 수 있다.
➜ 이러한 방식이 바로 파이프라이닝(Pipelining) 이라고 부르는 기능입니다.
파이프라이닝을 도입하면서 Redis는 네트워크 왕복 시간(RTT, Round Trip Time)을 최소화해, 단순히 명령어 처리 속도뿐 아니라 네트워크 지연까지 개선할 수 있으며
Redis 서버가 각 네트워크 요청에 대해 소켓 I/O를 수행할 때 read, write의 system call이 발생하여 사용자 영역에서 커널영역으로 이동하면서 context switch가 발생하는데 이것이 엄청난 속도 저하를 초래하기 때문에 성능에 있어서 큰 기여를 한다고 한다.
Redis는 이제 선택적으로 스레드를 사용하여 I/O를 처리할 수 있으며, 이를 통해 파이프라이닝을 사용할 수 없는 경우에도 단일 인스턴스에서 처리할 수 있는 작업 수를 2배로 늘릴 수 있다고 한다.
Redis 6.0 전과 후
Redis 6.0 이전

- 이벤트 루프(메인 스레드)가 epoll/kqueue 같은 I/O 멀티플렉싱 결과를 보고 소켓이 읽기/쓰기 준비됐음을 감지.
- 준비된 소켓에 대해 메인 스레드가 바로 readQueryFromClient()를 호출해 소켓에서 데이터(네트워크 버퍼)를 읽고, 수신된 바이트로부터 명령을 파싱하고(processCommand 준비), 명령을 실행(processCommand).
- 결과 응답 생성 후 writeToClient()로 바로 소켓에 쓰기를 시도.
이 방식은 구현이 단순하고 동시성 이슈가 없다는 장점이 있지만, 소켓 읽기/쓰기(시스템콜, 커널→유저 공간 복사 등)에 메인 스레드 시간이 많이 소모되면 전체 처리량이 제한.
Redis 6.0 이후

- 이벤트 감지 (Main thread + OS)
메인 스레드(또는 이벤트 라이브러)는 epoll/kqueue 같은 메커니즘으로 “어떤 클라이언트 소켓이 읽기/쓰기 가능”한지 감지. - I/O 위임 준비 (Insert io_threads_list)
감지된(ready) 소켓을 메인 스레드가 즉시 처리하지 않고 I/O 작업을 수행하도록 I/O Thread List(예: io_threads_list)에 등록한다. 메인 스레드는 어떤 클라이언트가 읽기/쓰기가 필요한지(또는 처리할 준비가 되었는지)를 표시하는 역할을 한다.
→ 그림 중간의 “IO-Multiplexing — Insert io_threads_list” 부분에 해당. - I/O 스레드들이 실제로 읽고(및 파싱) 씀 (IOThreadMain → readQueryFromClient)
I/O 스레드 풀(IOThreadMain 들)이 io_threads_list에서 할당을 받아 소켓에서 실제로 바이트를 읽어들인다.
(read/recv / SSL_read 등).
읽은 바이트를 기반으로 명령(프로토콜)을 부분적으로 또는 완전히 파싱해 둘 수 있있다. - 메인 스레드가 명령 실행 (processCommand)
메인 스레드는 주기적으로(또는 I/O 스레드 작업 종료를 확인한 후) clients_pending_read 리스트를 순회해서, I/O 스레드가 준비해 둔 명령(또는 아직 파싱이 덜 됐으면 메인 스레드가 마무리 파싱)을 실제로 실행.
이때, 실제 데이터 구조(해시/리스트/정렬 등) 변경과 명령 실행은 메인 스레드가 단일 스레드로 책임지므로, 기존 Redis의 원자성과 일관성 모델이 그대로 유지됩니다. 즉, 동시성 제어(락)를 도입하지 않아도 된다. - 결과는 쓰기 대기 큐에 적재 (pending write)
메인 스레드가 명령을 실행하고 응답을 만들면, 해당 클라이언트를 pending write 큐(또는 clients_pending_write) 에 넣는다. 이 큐는 응답을 소켓으로 보내야 하는 클라이언트 목록. - 실제 응답 전송: 메인 스레드 또는 I/O 스레드가 쓰기
응답 전송(특히 큰 응답이나 많은 클라이언트에 대한 전송)은 I/O 스레드가 실제로 소켓 쓰기를 수행하도록 위임할 수 있다. 읽기/쓰기를 I/O 스레드가 담당하며, 쓰기 역시 Threaded I/O가 처리해 메인 스레드의 부담 줄인다.
이때 I/O 스레드 = Threaded I/O
주의할 점 - 무조건 Threads 수를 늘려야할까?
Redis에서 작성된 영어 주석을 번역해보면,
Redis는 대부분 단일 스레드로 작동하지만, UNLINK와 같은 일부 스레드 작업, 느린 I/O 접근 등은 별도의 스레드에서 수행하는데
기본적으로 스레딩은 비활성화되어 있으며, 레디스는 적어도 4개 이상의 코어를 가진 기계에서만 활성화하는 것을 권장한다고 한다.
또한, 8개 이상의 스레드를 사용하는 것은 크게 도움이 되지 않을 것이다.
또한 Redis 인스턴스가 CPU 시간의 상당 부분을 사용할 수 있을 때만(CPU 리소스에 여유가 있을 때) 스레드 I/O를 사용하는 것을 권장하며 그렇지 않으면 이 기능을 사용할 이유가 없다. 라고 했다.
아래와 같이 redis.conf에 지정하여 io-threads의 수를 커스텀할 수 있으며
# redis.conf
io-threads 4 # thread 갯수
io-threads-do-reads no # 쓰기 작업에 threads가 쓰일지
# 이 설정 지시사항은 CONFIG SET을 통해 런타임에 변경할 수 없다.io-threads가 1이면 평소처럼 메인 스레드만 사용한다.
I/O 스레드가 활성화되면, 레디스는 쓰기를 위한 스레드만 사용합니다. 즉, write(2) 시스템 호출을 스레드화하고 클라이언트 버퍼를 소켓으로 전송합니다. 그러나 읽기와 프로토콜 파싱의 스레딩도 가능하며, 다음의 io-threads-do-reads-no로 설정할 수 있습니다:
"Usually threading reads doesn't help much." ➜ 일반적으로 읽기 스레딩은 크게 도움이 되지 않는다.
또 해당 글귀를 읽어보지 않았다면 무작정 스레드를 늘리고 redis를 썼을 것 같은데, 저렇게 권장 사항을 읽어보고 다시 한번 느꼈다.
"무작정 적용하지 말기...". 또한 read에 있어서는 이미 I/O Multiplexing으로 인해서인지 크게 도움이 되지 않는다고 하니 CPU Utilization Rate에 여유가 있고, 쓰기 연산에서 지연이 클 것 같은 경우 컴퓨팅 리소스의 코어 수를 고려하여 threading을 진행해야할 것 같다.
'Computer Science > Database' 카테고리의 다른 글
| [Redis] Redis 뜯어보기 3 - Redis Pub/Sub 동작 방식 (2) | 2025.08.12 |
|---|---|
| [Redis] Redis 뜯어보기 2 - redis 소스 코드 뜯어보기 (6) | 2025.08.11 |
| [Database] MySQL Index 적용해보기 (0) | 2025.03.25 |
| [Database] 윈도우 함수(Window Function) (0) | 2025.02.21 |
| [MongoDB] 채팅 데이터 저장을 위한 Mongo DB (1) | 2024.10.01 |


