
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- spring boot
- mysql
- 배포
- 해커톤
- ORM
- Java
- 스프링 부트
- 웹 서버
- 스프링 시큐리티
- 자바
- 가상화
- Container
- 스프링
- spring cloud
- JPA
- 데이터베이스
- virtualization
- Hackathon
- Redis
- CS
- 백엔드
- Spring
- vm
- computer science
- Spring Security
- 컨테이너
- 영속성 컨텍스트
- CI/CD
- 스프링 배치
- 도커
- Today
- Total
개발 일기
[Redis] Redis 뜯어보기 2 - redis 소스 코드 뜯어보기 본문
이전 글에서는 Redis가 클라이언트로부터 들어오는 명령어를 독립적으로 처리하거나, 파이프라인으로 한 번에 받더라도 I/O 멀티플렉싱을 통해 싱글 스레드에서 처리하는 구조를 살펴봤습니다. 이번 글에서는 소켓으로 들어온 명령어가 파싱된 이후 Redis 내부에서 어떻게 처리되는지, processCommand()를 중심으로 자세히 들여다보겠다.
Redis 명령어 처리 및 전파 흐름
시작에 앞서 전체적인 흐름은
입력 버퍼에서 명령어를 파싱 → 타입별 Command 함수 호출 → DB 접근 → 클라이언트 응답 → AOF/Replication 전파
Redis에서 클라이언트 명령어가 들어오면, 싱글 스레드 기반의 이벤트 루프가 이를 I/O Multiplexing을 통해 처리한다.
전체 흐름을 단계별로 보면 다음과 같다.

첫번째, 클라이언트 연결 및 이벤트 루프에 readQueryFromClient()
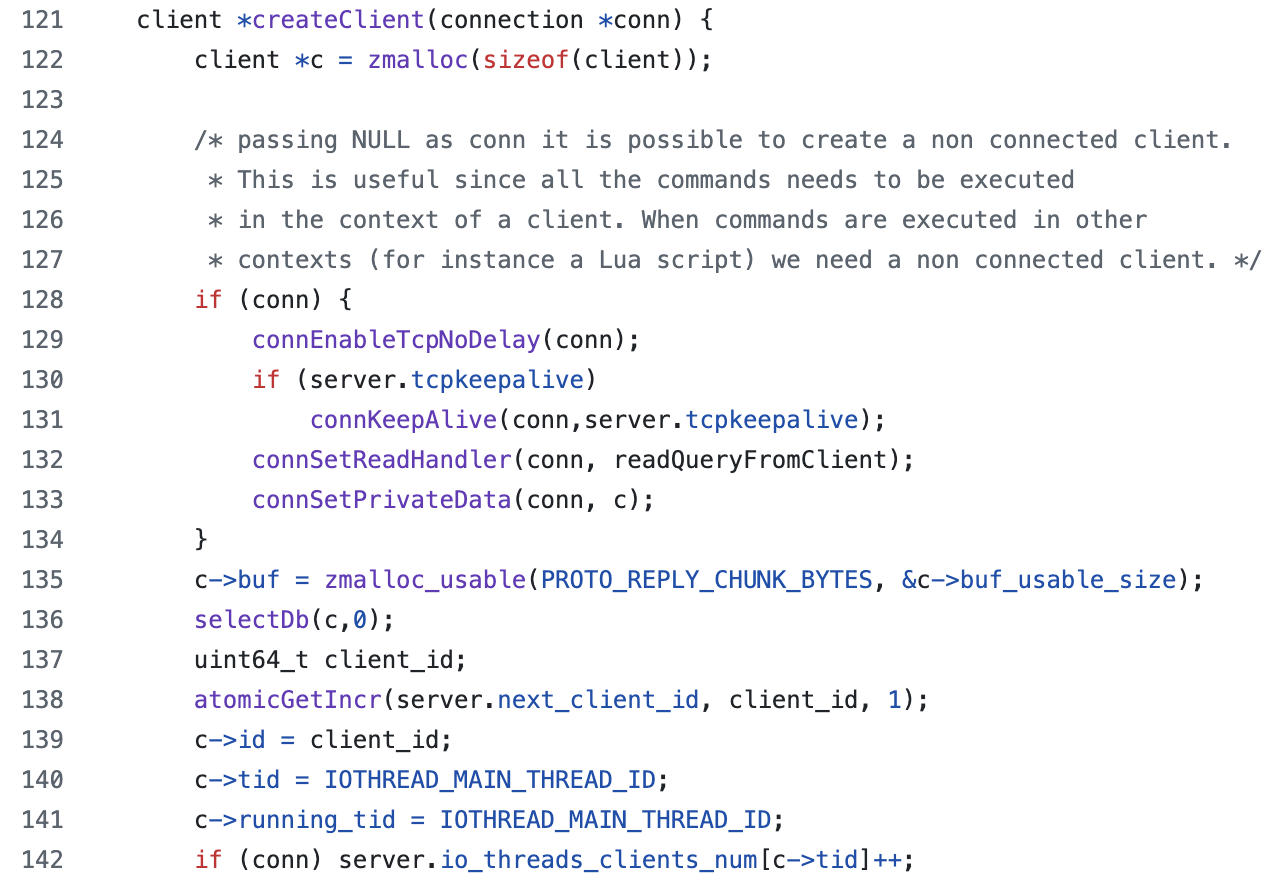
redis/src/networking.c의 client *createClient(connection *conn)로 Redis에서 클라이언트 하나가 연결될 때마다 독립적인 client 구조체 생성한다.
이때, if문 내에서 connEnableTcpNoDelay(conn)를 통해서 Nagle 알고리즘을 비활성화한다고 한다.
Nagle 알고리즘을 간단하게 말해서 작은 데이터를 바로 보내지 않고, ACK를 기다렸다가 묶어서 전송하는 것으로 네트워크 효율성이 증가하지만 그만큼 지연이 발생한다.
따라서 TCP_NODELAY로 Nagle 알고리즘을 비활성화하여 작은 패킷 단위도 지연 없이 전송하도록 만드는 것이다.
Redis 명령은 대부분 작은 문자열 명령어이며 인메모리 캐시인 만큼 지연 없이 클라이언트에게 바로 응답하는 것이 중요하기 때문이다.
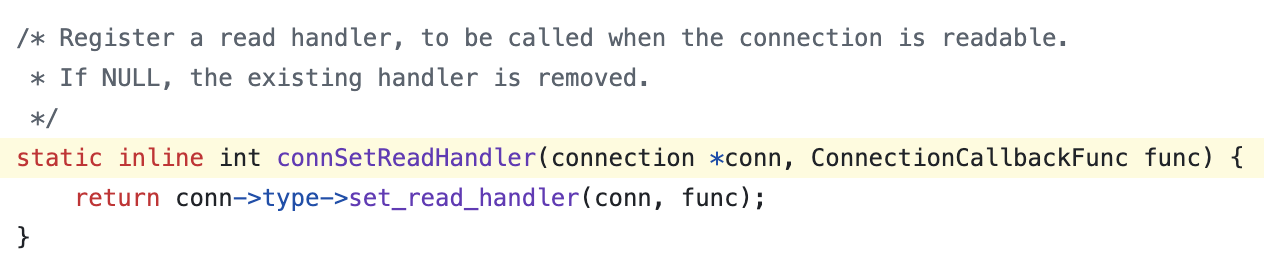
그 다음 connSetReadHandler(conn, readQueryFromClient);에서 해당 클라이언트 소켓에 읽기 이벤트 핸들러를 등록하는 코드로 이 소켓에 데이터(읽기 이벤트)가 들어오면 readQueryFromClient()를 호출하라는 것이며 TCP 요청의 경우 conn->type은 TCP 관련 구조체가 되어서 TCP 타입의 set_read_handler()가 호출된다.
set_read_handler()는 ConnectionCallbackFunc로 전달된 readQueryFromClient()를 이벤트 루프에 등록하여, 이 소켓에서 읽기 이벤트가 발생할 때 호출될 함수로 지정한다.
두번째, 클라이언트 연결 및 소켓에서 READ 후 Command Parsing & 명령어 실행 & 상태 관리
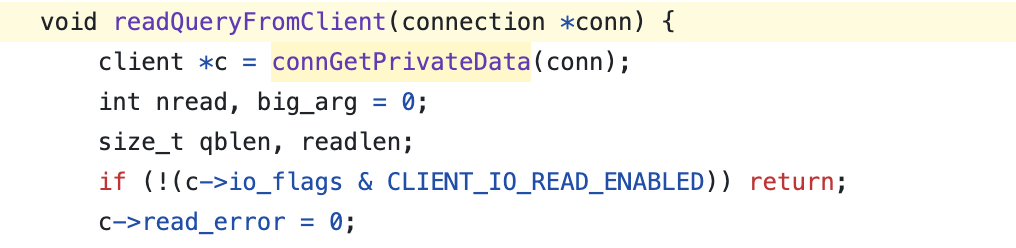
먼저, 소켓(conn)과 연결된 client 구조체를 가져온다.
그런 다음 읽기를 위한 읽기 버퍼(querybuf)를 세팅을 한 다음,
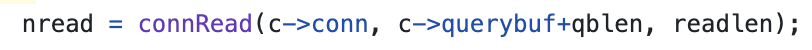
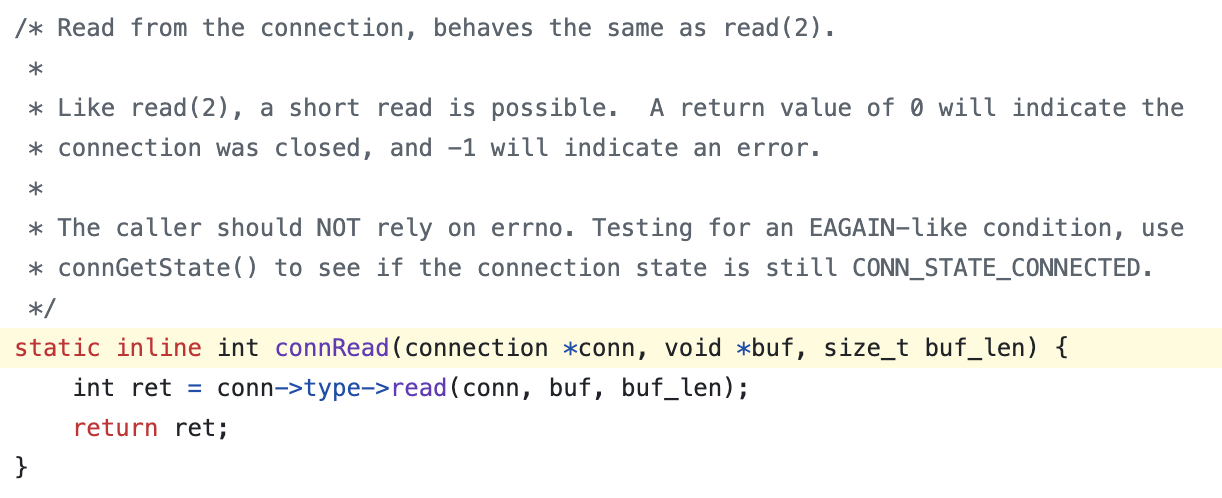
해당 메소드를 통해 Client Socket에서 데이터를 읽어오는데 conn->type에서 연결 유형별(예: TCP, Unix socket) 함수 포인터 구조체로 읽기 함수를 호출하는데 해당 read() 메소드 자체가 system call은 아니고 추상화한 함수 포인터를 통해 호출되는 읽기 함수이다.
소켓에서 데이터를 읽어 클라이언트의 query buffer에 추가한다.
이때 또 중요한 점은 non-blocking 소켓을 활용한다는 점이다.
read() 또는 recv()를 호출하면 데이터가 올 때까지 호출한 스레드가 멈춤(대기)을 하게 되면 클라이언트가 아직 데이터를 보내지 않았으면 스레드가 기다리며 아무 작업도 못 하겠지만 non-blocking 소켓의 도입으로 데이터를 기다리지 않고 즉시 반환하여 스레드는 다른 작업을 계속 수행할 수 있게 된다.
해당 부분은, 싱글 스레드 이벤트 루프 구조로 동작하는 Redis가 여러 클라이언트의 소켓을 순차적으로 확인하며 데이터 전송 여부를 감지하기 위해 반드시 필요한 기능이라고 생각한다.


이제 소켓에서 데이터를 read한 후 client 구조체의 queryBuf(읽기 버퍼)에 완전한 명령어가 있는지 processInputBuffer()를 호출하면서 계속 확인한다.
내부적으로는
INLINE: processInlineBuffer(c) 호출 (단일 명령어 파싱)
MULTIBULK: processMultibulkBuffer(c) 호출 (파이프라인 명령어 처리)
이 두 개에 따라 다른 메소드가 실행되며 완전한 명령어가 들어왔다고 판단되면 해당 명령어를 파싱한다.

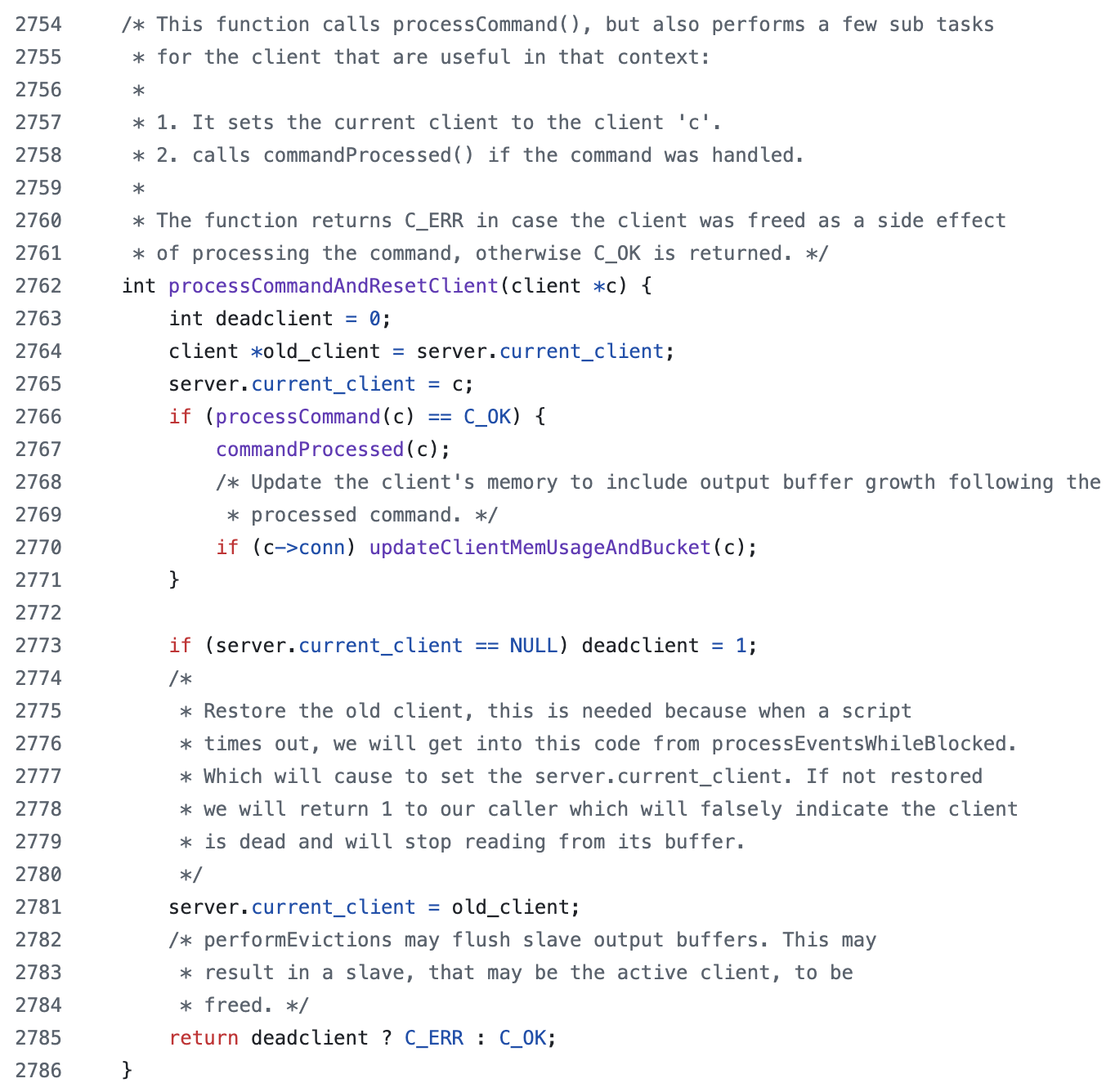
명령어가 파싱이 끝나면 processCommandAndResetClient()가 호출된다.
해당 메소드 내부의 processCommand(c)를 통해 실제 명령어를 실행하기 위한 준비 단계 및 검증을 거쳐 실제 명령어를 실행하게 되며 그 후 commandProcessed(c)와 updateClientMemUsageAndBucket(c)를 통해서 서버 통계, 내부 상태 업데이트 및 메모리 사용량 갱신하게 된다.
세번째, 명령어 처리를 위한 준비 단계
이제 server.c로 넘어왔다.

우선 해당 processCommand(Client *c)에서 보이듯이 Client 구조체만 넘겨 줬다고 어떻게 명령어를 알 수 있을까 했는데 아래 코드와 같이 server.h에 정의된 client 구조체의 필드 **argv에 명령어가 담겨있다고 한다.

다시 processComand(c)로 돌아와서 내부 동작과정을 보자.
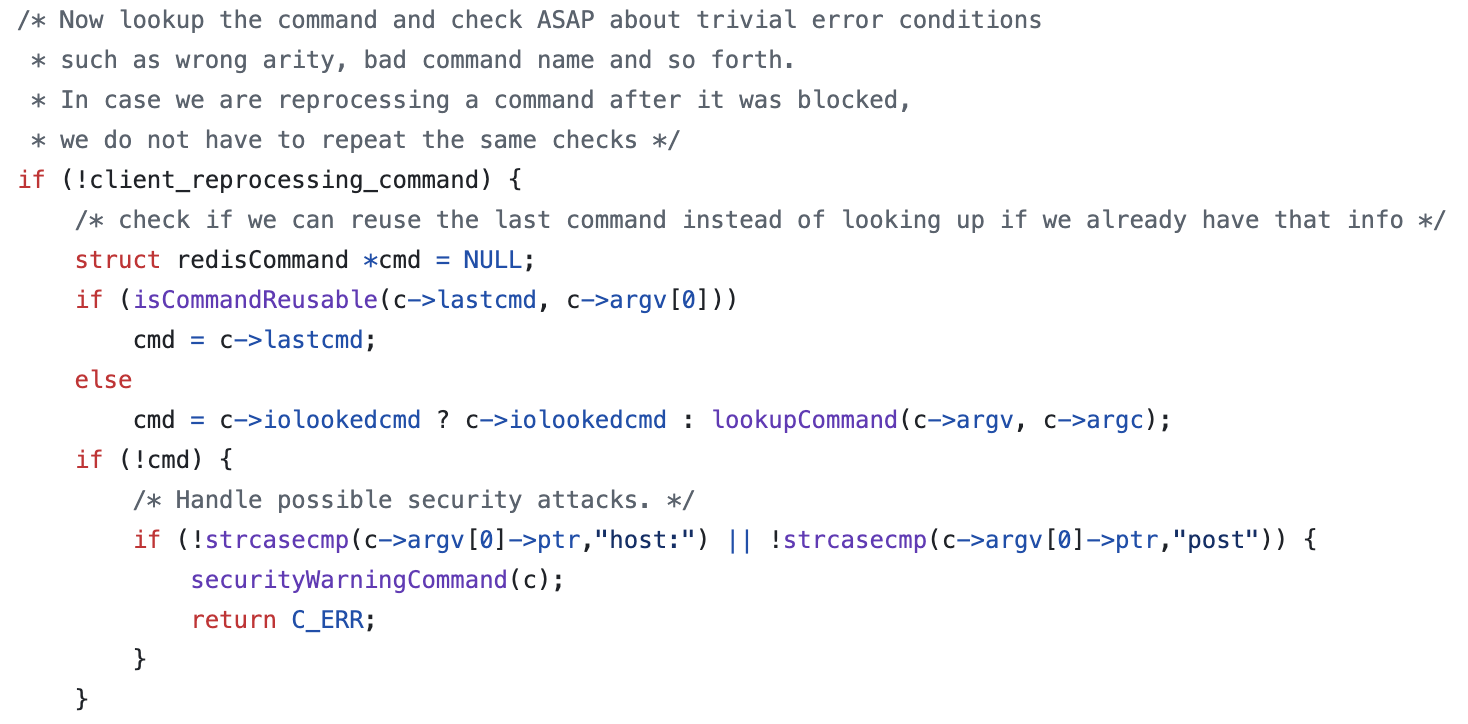
해당 부분을 보면 우선 if(!client_reprocessing_command)에서 client_reprocessing_command는 아래에서 알 수 있듯이 c->cmd이다.


위에서 보면 cmd(현재 실행 중인 명령어)가 client 구조체의 멤버 변수 중 하나로 (*c).cmd 즉, 해당 client의 cmd 변수에 접근하는 것이다.
그래서 다시 processComand()의 if문으로 돌아와서 c->cmd를 통해서 이번 명령이 재처리(reprocessing) 가 아니면(= c->cmd가 아직 없음)만 아래 검사를 수행하도록 한다.
만약 재처리가 아니라면, 명령 포인터를 초기화한 후 다음 if문으로 넘어간다.
if (isCommandReusable(c->lastcmd, c->argv[0])) cmd = c->lastcmd;에서 lastcmd 필드를 조회해서 해당 client의 이전 명령어를 이번에 들어온 명령어인 argv[0]과 비교하여 재사용 가능한지 확인하여 명령어 포인터에 할당한다.
만약, commandReusable()이 false라면 c->iolookedcmd도 확인하는데 이때 I/O 스레드(=threaded I/O =worker thread)에서 미리 찾아 둔(lookup) 명령 포인터 캐시이다. 이것은 입력 파싱이 I/O 스레드에서 이뤄질 때, 그 자리에서 argv[0](명령 이름)로 lookupCommand()를 해보고, 결과를 c->iolookedcmd에 꽂아두는 것인데
만약 io-threads 설정이 1으로 event loop를 담당하는 main thread만 있고 worker thread가 존재하지 않는다면 null일 것으로 예상된다. (I/O 스레드는 명령 실행은 절대 안 한다!)

그런데 또 I/O thread가 찾아둔 명령어 조차 없다면 그제서야 lookupCommand(c->argv, c->argc)를 진행한다.
- c->argv의 argv는 명령어와 인자들의 배열으로 예시로 다음을 들 수 있다. ex) ["SET", "foo", "bar"]
- c->argc의 argc는 인자의 갯수로 ["SET", "foo", "bar"]인 경우 3이다.
lookupCommand()에서는 다시 lookupCommandLogic()을 호출하는데 이때, server.commands라는 dict *commands와 int strict가 추가로 인자로 넣어주는데
server.commands는 Redis에서 등록된 명령어 사전(dict)이며 명령어 이름에 대해 해당하는 redisCommand 구조체와 매핑시켜주는 것이다.
그런다음 lookup까지 거치면 cmd에 요청한 명령어에 따른 redisCommand 인스턴스가 담길 것이다.
이후, 명령 존재 여부 체크 & 인자 개수 체크 & 보호 명령어 체크(CMD_PROTECTED)를 통해 해당 명령어를 실행해도 괜찮은지 최종 검증의 단계를 거친다.
네번째, 명령어 테이블(redisCommandTable)이 초기화 되는 과정 - 세번째에서 조금 더 깊은 이야기
레디스 서버가 시작될때 dictionary에 모두 명령어 정보를 넣어준다고 한다.
해당 dictionary는 server.c의 void initServerConfig(void)에서

해당 코드와 같이 초기화되는데,
- server.commands = dictCreate(&commandTableDictType);
- server.orig_commands = dictCreate(&commandTableDictType);
이 두 개에서 빈 해시테이블이 초기화되며
populateCommandTable()에서는 redisCommandTable 배열을 순회하며 각 명령어 구조체를 초기화한 후
두 개의 해시 테이블(server.commands, server.orig_commands)에 등록시킨다.
또 다시 redisCommandTable 배열을 순회한다고했을때 해당 Table은 redis/src/commands.def에서 작성된 명령어 정보들을 기반으로 초기화되는데 해당 파일을 보면,
commands.def
(좌) CLUSTER과 관련된 명령어 일부 , (우) CLIENT와 관련 명령어 일부

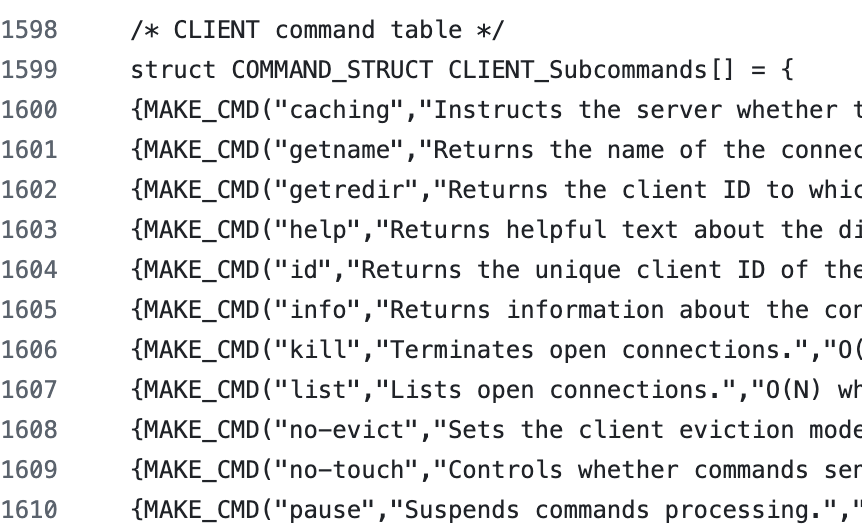
(좌) CONFIG와 관련된 명령어 일부 , (우) PUBSUB과 관련 명령어 일부


이 외에도 정말 다양한 명령어가 정의 되어 있었으며, 가장 아래에는
bitmap, cluster, connection, geo, hash, hyperloglog, list, pubsub, scripting, sentinel, server, set, sorted_set, stream, string, transactions로 분리된 Main command까지 잘 정의 되어 있는 것을 확인할 수 있었다.

이렇게 정의된 것을 바탕으로 Redis Server가 시작되는 시점에 commands.def의 내용을 끌고와서 dict에 저장시키고 server.commands변수에 담아서 lookup(명령어 조회)하는 과정을 거치는 듯 하다.
그렇게 찾은 reidsCommand 구조체를 processCommand()의 cmd 변수로 넣어준다.
이때 문자열에 해당하는 command가 딕셔너리에서 발견되지 않으면 에러를 발생시킨다.
다섯번째, processCommand()에서 실제 명령어 처리
참고로 아직까지 processComand() 내부이다.
이 단계까지 완료되면 c->cmd에 실제 실행할 redisCommand 포인터가 들어가있을 것이고 여러 검증 단계를 거쳤을 것이다.
이제 processCommand()의 마지막 부분까지 왔고 드디어 Exec the command 명령어를 실행하기 시작한다.

그러나 이때 아주 중요한 포인트가 있다.
클라이언트가 MULTI 상태인지 확인하는 작업이다.
클라이언트가 MULTI 상태라는 것은 Redis에서 트랜잭션이 시작되었다는 의미한다.
트랜잭션 모드에서는 여러 개의 명령어를 한 번에 실행해야 하므로, 일반적인 경우처럼 명령어가 들어오는 즉시 실행하지 않는다.
대신 EXEC, DISCARD, MULTI, WATCH, QUIT, RESET 같은 트랜잭션 관련 명령어가 아닌 경우, 들어온 명령어를 큐에 쌓아둔다.
여기서 queueMultiCommand(c, cmd_flags)는 트랜잭션 큐에 명령어를 추가하는 역할을 하고, addReply(c, shared.queued)는 클라이언트에게 "QUEUED"라는 응답을 보내, 명령어가 실행 대기 중임을 알린다.
이렇게 큐에 명령어를 모아두는 이유는 트랜잭션이 완료될 때까지(즉, 클라이언트가 EXEC 명령을 보낼 때까지) 각각의 명령을 실행하면, 트랜잭션의 원자성(Atomicity)을 보장할 수 없기 때문이다.
즉, 모든 명령어를 모아두었다가 한 번에 실행해야 트랜잭션 전체가 실패하거나 성공하는 것을 보장할 수 있고, 중간에 다른 클라이언트가 데이터를 변경하는 상황도 방지할 수 있다.
만약 MULTI 모드가 아니라면 바로 call()을 호출하게 된다.

여기서, cmd에 저장된 redisCommand를 실행시킨다.

이 부분은 네번째 순서와 연결되기도 하는데 아까전에는 설명을 생략했지만 잠깐 실행될 명령어에 대해 어떤 메소드가 실행될지 알 수 있는지 조금 더 구체적으로 파보자.
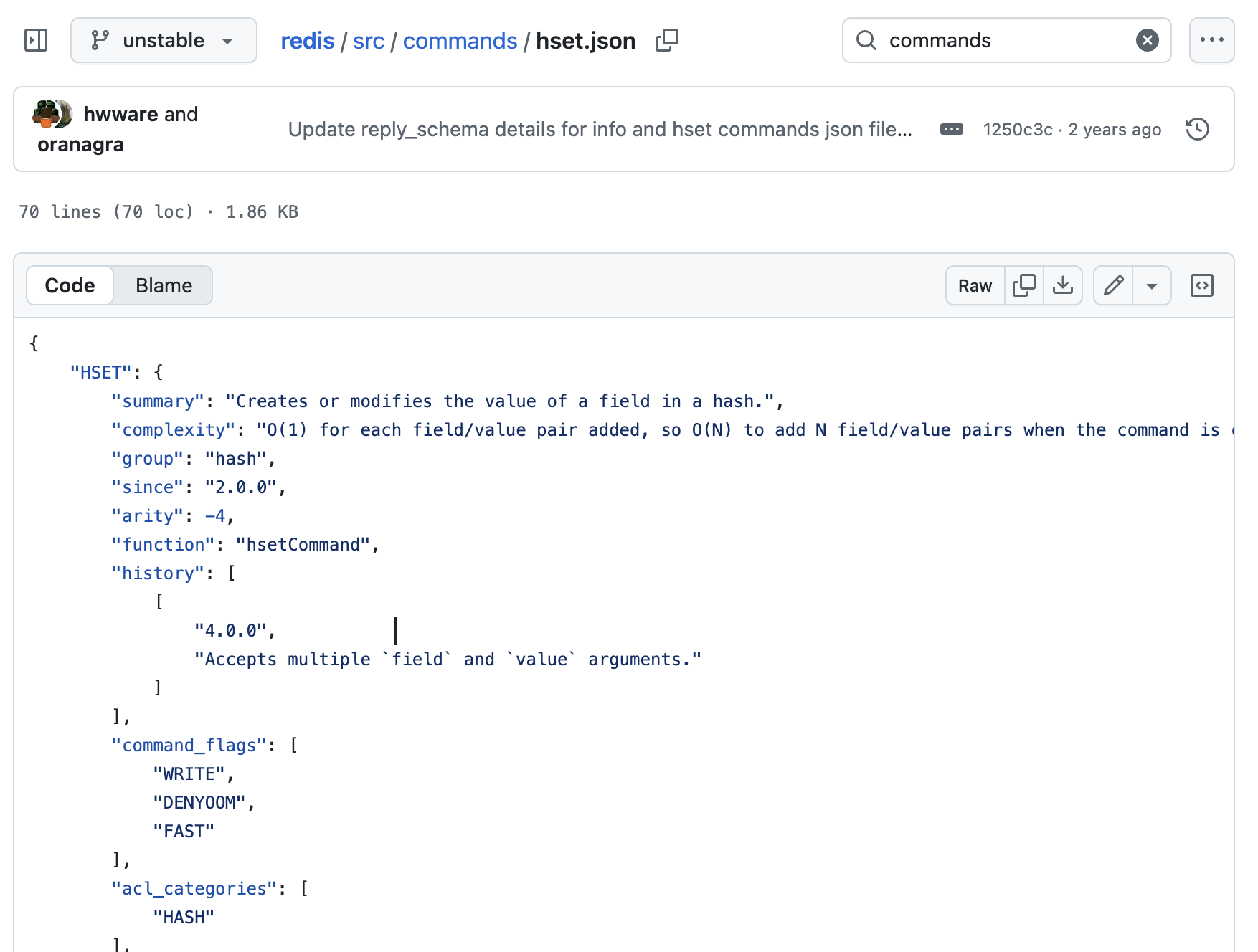
여기서 보이는 것과 같이 redis/src/commands/hset.json에 HSET 명령어의 “설명서 + 실행 스펙 + 실행 함수 매핑” 역할을 하는 메타 데이터 정보들이 포함되어 있다.
특히, 저기 보면 "function" : "hsetCommand"가 있는 것을 볼 수 있고 이 JSON이 “HSET 명령어가 호출되면 C에서 hsetCommand()라는 함수를 실행해야 한다”는 뜻을 표현해주는 것이다.
( redisCommandTable[] 안에 "HSET" → hsetCommand 매핑 )

- Redis 빌드 과정 make가 돌 때 commands/*.json(Command 메타데이터)이 변경되었거나 없으면 utils/generate-command-code.py를 Python 인터프리터로 실행시켜서 .def 파일(src/commands.def)을 생성
- 서버 시작할 때 initServerConfig() 메소드 내에서 populateCommandTable() (→ server.c)가 호출된다.
이 함수가 commands.c 안의 정의들을 읽어 Redis 내부 dict(server.commands)에 삽입. - 위 이미지와 같이 commands.c에 commands.def를 include하여 거대한 명령어 테이블인 redisCommandTable을 초기화 시키는 것인데, commands.def가 #include "commands.def"를 통해서 컴파일 타임에 삽입된다.
c->cmd->proc(c)에서 client 구조체 인스턴스 내부의 cmd에 redisCommandTable에서 lookup한 redisCommand가 들어가 있고 거기에 저 json에 담겨있던 trigger될 function을 들고있다.
그래서 이제 해당 코드를 통해 드디어 명령어를 실제로 처리하는 코드가 실행된다.!!!!
계속해서 "HSET" 명령어를 예시로 hsetCommand메소드가 실행될텐데 이러한 메소드들은 redis/src/t_*.c 내부에 구현되어 있다.
- src/t_string.c → 문자열 관련 명령어 (setCommand, getCommand, …)
- src/t_list.c → 리스트 관련 명령어 (lpushCommand, lpopCommand, …)
- src/t_hash.c → 해시 관련 명령어 (hsetCommand, hgetCommand, …)
- src/t_set.c → 집합 관련 명령어 (saddCommand, smembersCommand, …)
- src/t_zset.c → 정렬된 집합 관련 명령어 (zaddCommand, zrangeCommand, …)
자, 예시로 보려는 hsetCommand도 역시 redis/src/t_hash.c에 구현되어 있다.
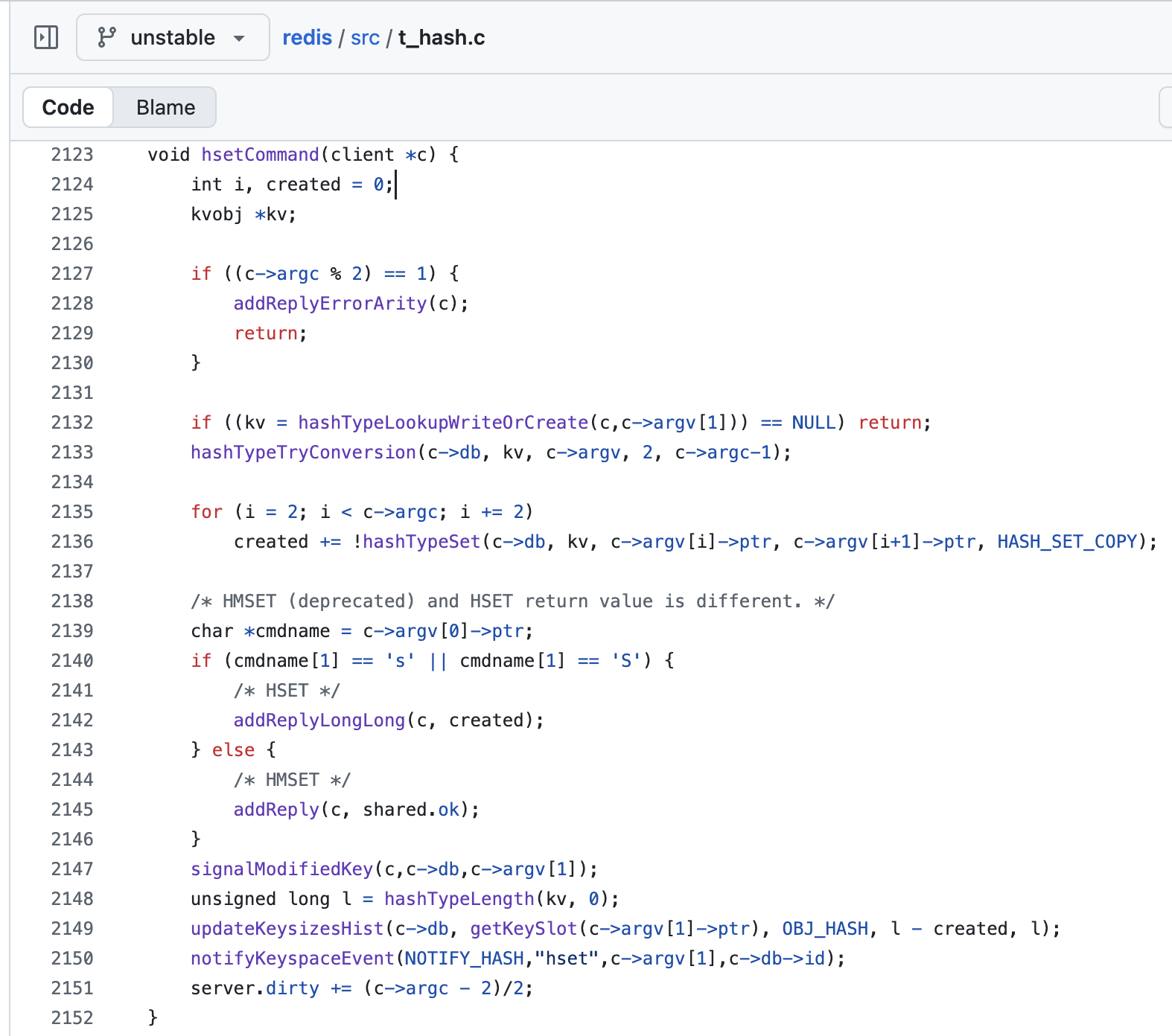
런타임 시점
processCommand() → lookupCommand() → c->cmd->proc 을 통해 결국 hsetCommand(client *c) 가 호출됨!
드디어 명령어가 실행됐다.
call() 내부에서 이후에 실행 시간, 슬로우로그, AOF/복제, 모니터링, 통계 처리 등 추가적인 처리가 발생한다고 한다.
여섯번째, 응답 생성되어 클라이언트로
드디어 명령어가 실행됐고 이제 응답을 Client로 반환시킬 차례다.
응답은 addReply*() 류 함수로 클라이언트 객체(client *c)에 저장한다.
"HSET" 명령어의 hsetCommand() 기준으로는 아래 코드이다.


- addReplyLongLong
- addReply
이렇게 두 개인데 오른쪽에서 볼 수 있듯이 addReplyLongLong 또한 내부적으로는 addReply로 처리하는 듯 하다.
그래서 addReply가 어떻게 동작하는지 보자.
addReply는 각 커맨드가 처리한 결과를 클라이언트의 출력 버퍼에 적재할 때 호출한다.

먼저 함수는 _prepareClientToWrite(c)를 호출하여, 해당 클라이언트가 쓰기 준비가 되었는지 확인하고 만약 준비가 되지 않았다면, 즉시 반환하여 이후 로직을 그만둔다.
Redis에서는 문자열 객체를 두 가지 방식으로 표현한다.
- 하나는 SDS(Simple Dynamic String) 형식 - 동적 문자열 라이브러리
: sdsEncodedObject(obj)가 참이 되어 _addReplyToBufferOrList(c, obj->ptr, sdslen(obj->ptr))가 호출된다.
여기서 obj->ptr는 실제 문자열 데이터이고, sdslen(obj->ptr)는 문자열 길이를 반환한다.
이 과정에서 SDS 문자열이 클라이언트의 출력 버퍼로 안전하게 복사된다.! - 다른 하나는 정수 인코딩
: 먼저 ll2string이라는 최적화된 함수를 사용하여 정수를 문자열로 변환한다.
변환된 문자열과 길이는 동일하게 _addReplyToBufferOrList로 전달되어 버퍼에 적재
만약 객체가 SDS도 아니고 정수도 아니라면, 이는 Redis 내부에서 처리할 수 없는 잘못된 객체 인코딩이므로 serverPanic("Wrong obj->encoding in addReply()")를 호출해 강제로 처리 중단.
addReply() → 커맨드 구현체가 처리한 결과를 클라이언트에게 전송하기 위해 안전하게 출력 버퍼에 쌓아주는 역할을 수행
_addReplyToBufferOrList()도 타고 들어가보자.
그 중에서 아래 코드 블록을 보려고 한다.
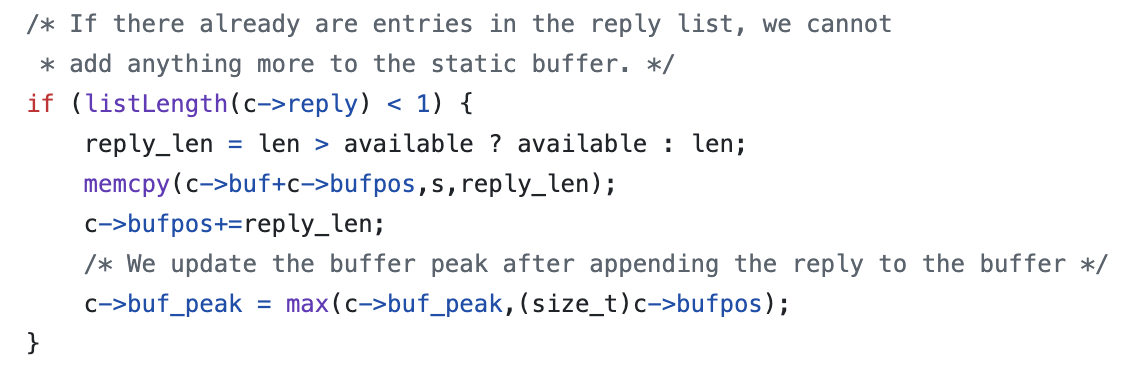
- 우선, c->buf는 클라이언트 구조체 내부의 정적 출력 버퍼 (버퍼의 시작 주소)
- c->bufpos는 현재까지 데이터가 쓰여진 offset (현재까지 버퍼에 쓰인 길이 (offset))
- memcpy(c->buf + c->bufpos, s, reply_len)가 실제로 데이터를 버퍼에 복사하는 부분
- c->bufpos += reply_len → 버퍼 위치를 갱신하여 다음 쓰기 위치로 이동
- c->buf_peak → 버퍼 사용량 최대값 기록 (통계용)
이때 만약, 버퍼가 가득 차거나 이미 리스트(reply list)에 다른 데이터가 존재하면 나머지는 리스트로 이동시킨다.
현재까지 상태에서는 아직 네트워크로 전송되지 않은 상태이다.
일곱번째, Redis에서 클라이언트로 응답이 전송되는 과정 (출력 버퍼부터 소켓 전송까지)
드디어 마지막이다.
현재까지 상태는 Client 구조체의 정적 출력 버퍼(c->buf)에 응답이 모두 작성된 상태이다.
addReply() 함수 내부에서는 _prepareClientToWrite()를 호출하는데,
이 함수의 역할은 작성된 응답을 실제로 소켓으로 전송할 준비를 하는 것이다.
여기서 중요한 동작은 이벤트 루프 등록!!

clientHasPendingReplies(c)는 이미 쓰기 이벤트가 등록돼 있는지 확인하는 것. 즉, 쓰기 이벤트가 등록되지 않았다면 putClientInPendingWriteQueue()가 실행된다.
즉, _prepareClientToWrite()를 통해 이 클라이언트를 쓰기 큐에 넣는 과정이 바로 소켓 쓰기 이벤트를 활성화시키는 시작점.
putClientInPendingWriteQueue()는 클라이언트를 실제 쓰기 이벤트로 바로 등록하지는 않고, 먼저 쓰기 대기 큐(PendingWriteQueue)에 넣고 플래그를 설정한다.
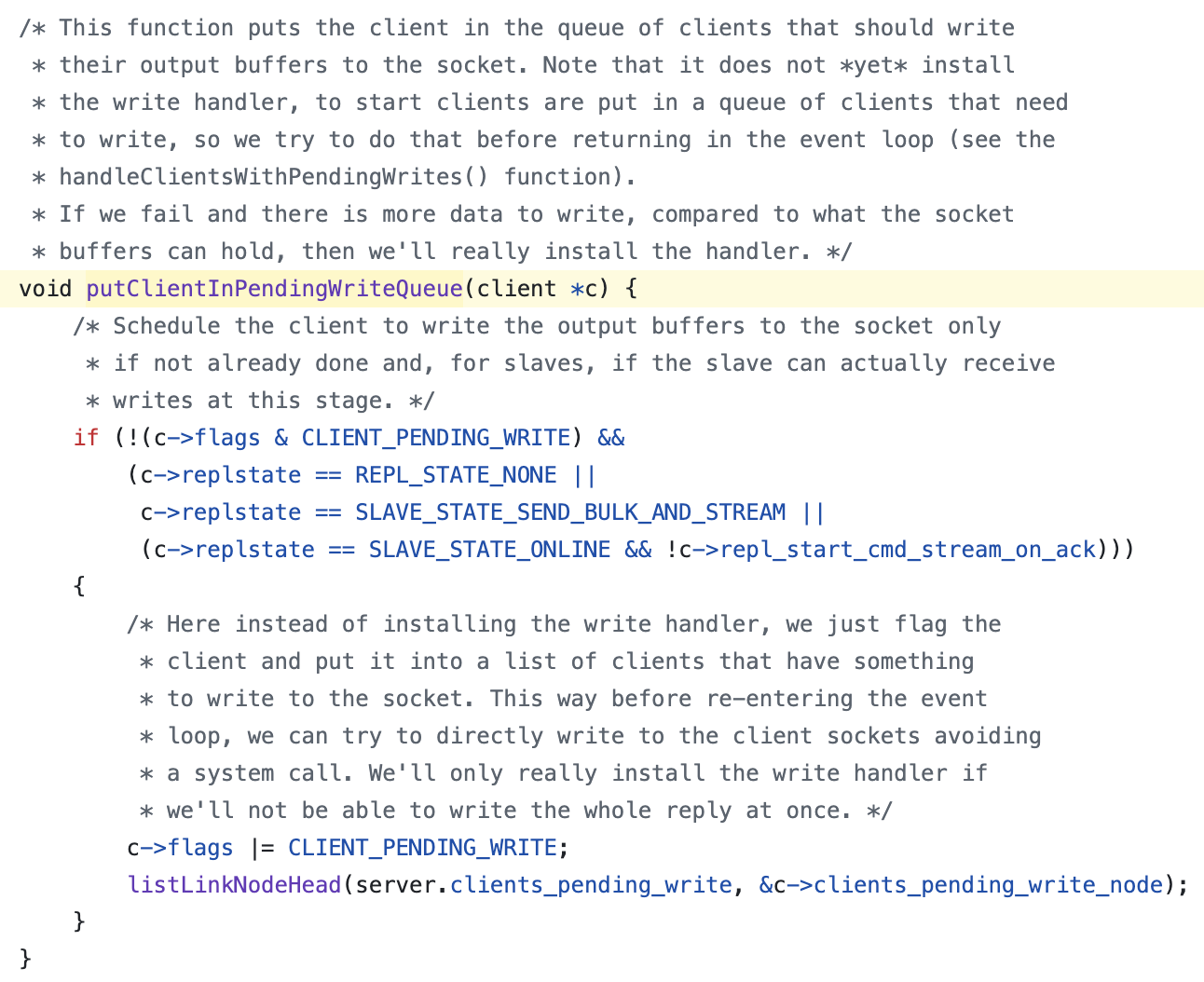
클라이언트의 CLIENT_PENDING_WRITE 플래그를 설정하여 “이 클라이언트에 전송할 데이터가 있다”는 것을 표시하고, server.clients_pending_write 리스트에 해당 클라이언트를 추가한다.
이렇게 하면 이벤트 루프에서 이 클라이언트를 확인할 수 있어진다.
이벤트 루프는 주기적으로 이 리스트를 확인하고, CLIENT_PENDING_WRITE 플래그가 설정된 클라이언트에 대해 소켓 쓰기 이벤트를 발생시킨다.
소켓 쓰기 이벤트가 발생하면 sendReplyToClient()가 호출되고, 이 함수는 내부적으로 writeToClient()를 호출.


writeToClient()는 클라이언트 구조체의 출력 버퍼에 있는 데이터를 실제 소켓으로 전송하며, 한 번에 전송할 수 있는 최대 바이트 수를 제한하면서 필요에 따라 반복해서 데이터를 전송한다.
전송이 완료되면 CLIENT_PENDING_WRITE 플래그를 해제하고, 버퍼가 비어 있으면 클라이언트 연결 유지 여부를 확인하고 필요하면 연결을 종료한다.
이렇게 해서 명령어 실행 결과가 안전하게 클라이언트에게 전달된다.
Socket 통신 응답 과정
이때 write()호출 시에는 실제로 커널의 소켓 송신 버퍼로 데이터를 복사한 것으로
이 시점까지는 아직 데이터가 네트워크를 통해 클라이언트로 나간 것은 아니고, 커널 버퍼 안에 존재한다.
OS 커널은 TCP/IP 프로토콜 규칙에 따라 패킷을 나눠서 클라이언트 소켓 쪽으로 전송한다.
클라이언트 쪽 OS 커널이 이 패킷을 수신하면, 클라이언트 소켓의 수신 버퍼에 데이터를 쌓고,
클라이언트 애플리케이션이 read() 혹은 recv()를 호출하면, OS 수신 버퍼에서 데이터를 애플리케이션으로 복사한다.
Redis를 평소에 아무 생각없이 사용하면서 이렇게 복잡하게 동작하는지 몰랐다.
Redis 소스 코드를 직접 뜯어보니 대략 어떻게 돌아가는지 감은 잡았다.
사실 100% 이해한 것은 아니지만 그래도 훨씬 이해한 기분이 든다.
'Computer Science > Database' 카테고리의 다른 글
| [Redis] Redis 뜯어보기 4 - Redis Cluster 사례 & HashSlot 원리 (3) | 2025.08.15 |
|---|---|
| [Redis] Redis 뜯어보기 3 - Redis Pub/Sub 동작 방식 (2) | 2025.08.12 |
| [Redis] Redis 뜯어보기 1 - 내부 구조 및 동작 방식(feat. I/O-Multiplexing) (3) | 2025.08.11 |
| [Database] MySQL Index 적용해보기 (0) | 2025.03.25 |
| [Database] 윈도우 함수(Window Function) (0) | 2025.02.21 |



