
- 분류 전체보기 (141)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- computer science
- 가상화
- mysql
- 데이터베이스
- 스프링 배치
- 영속성 컨텍스트
- HTTP
- Container
- 스프링 부트
- 백엔드
- CS
- Spring Security
- ORM
- 스프링 시큐리티
- Spring
- 배포
- 도커
- spring cloud
- spring boot
- 웹 서버
- web server
- CI/CD
- 컨테이너
- 스프링
- vm
- spring batch
- Java
- JPA
- virtualization
- 자바
- Today
- Total
개발 일기
[Java] JAVA 코드가 실행되기까지... (Java = Interpreter + Compiler) 본문
[Java] JAVA 코드가 실행되기까지... (Java = Interpreter + Compiler)
개발 일기장 주인 2025. 3. 27. 16:20→https://ai-back-end.tistory.com/119
[Java] JVM 메모리 구조(Method-Static, Heap, Stack)
그전에 JVM에 대해 다시 떠올려보자. JVM 이란 Java Virtual Machine의 약자이며, 자바 가상 머신이라고 한다.자바 애플리케이션을 실행하기 위한 가상 환경자바 바이트코드(.class 파일)를 특정 운
ai-back-end.tistory.com
이전에 작성했던 블로그에서 단순히 JVM안에만 갇혀서 생각했다가 타 프로그램이 실행됐을때와 뭔가 다르다는걸 알게됐다.
프로그램이 실행될 때 소스 코드나 실행 파일이 가상 메모리를 거쳐 RAM에 로드되고, 그 과정에서 변수들이 메모리 영역(Code, Heap, Data, Stack)에 로드된다고 했는데 Java는 또 JVM이 이러한 것을 처리하는데 차이점이 제대로 와닿지 않았다.
프로세스의 메모리 영역과 Java Application 실행 시 JVM의 메모리 영역이 어떤 상관관계가 있는지 알아보고 위 블로그의 심화버전?을 작성해보고자 한다.
우선, Java Application이 실행되는 과정은 위에 내가 이전에 작성했던 블로그를 참고하면 될 것같다.
이때 나는 조금 더 프로세스의 관점에서 보고자 한다.

Java 코드가 실행되면
- Java 소스 코드 컴파일
- Java 소스 코드(.java 파일)는 Java Compiler (javac)에 의해 바이트코드(.class 파일)로 컴파일
- Class 파일 로딩
- 컴파일된 .class 파일은 JVM에 의해 메모리로 로드되지 않고, Class Loader를 통해 Method Area(메서드 영역)에 로드
- JVM의 메모리 영역
- JVM은 Runtime Data Area를 할당받습니다. 이 영역은 여러 서브 영역으로 나뉘며, 그 중 Method Area는 클래스의 메타데이터와 바이트코드, 상수 풀 등을 저장
- 바이트코드 실행
- JVM이 처음에는 바이트코드를 인터프리터(Interpreter)로 처리하여 기계어(Binary Code) 변환
- Execution Engine
- Execution Engine은 인터프리터와 JIT(Just-In-Time) 컴파일러를 포함하여 바이트코드를 실행
- 인터프리터는 바이트코드를 한 줄씩 처리하여 실행
- JIT 컴파일러는 자주 실행되는 코드(HOTSPOT)를 감지하고, 이를 기계어(Binary Code)로 컴파일하여 RAM에 저장
- Execution Engine은 인터프리터와 JIT(Just-In-Time) 컴파일러를 포함하여 바이트코드를 실행
- JIT 컴파일러(JIT, Just-In-Time)의 역할
- JIT 컴파일러는 코드 실행 중에 자주 호출되는 메서드나 코드 블록을 핫스팟(Hotspot)으로 감지하고, 해당 코드를 기계어로 변환하여 최적화
- 변환된 기계어는 RAM에 저장되고, 이후에는 CPU가 이를 직접 실행
- CPU의 실행
- CPU는 JIT 컴파일러가 생성한 기계어를 직접 실행합니다. CPU가 실행하는 과정에서 다시 검증하고 최적화


컴파일 언어과 인터프리터 언어 비교
컴파일 언어
1. 컴파일 자체에 시간이 걸릴 수 있으며 컴파일 오류가 발생할 시 다시 해야한다.
2. BUT, 이미 컴파일 된 프로그램이라면 실행만 시키면 된다.(즉, 실행속도에서 이점)
3. 컴파일 시 모든 오류가 검출되므로, 런타임 전에 대부분의 오류를 발견
4. OS 이식성이 낮다 ➡️ 컴파일된 실행파일은 기계어인데 OS마다 호환되는 기계어가 다르다.
인터프리터 언어
1. 런타임 시점에 바이트 코드 또는 소스 코드를 한 줄씩 인터프리팅을 해야하기에 실행이 느릴 수 있다.
2. 런타임 오류가 발생할 확률이 높다.(컴파일 오류 확인 불가)
3. OS 이식성이 높다 ➡️ 플랫폼에 적합한 인터프리터만 가지고 있다면 실행가능하다.
정리해보면
기타 애플리케이션은 OS에 의해 프로세스 메모리 영역을 할당받는다.
반면, Java 애플리케이션은 JVM(Java Virtual Machine)을 통해 실행되며, JVM은 OS로부터 Runtime Data Area라는 메모리 영역을 할당받는다.
JVM은 이 Runtime Data Area에서 프로그램 실행에 필요한 데이터를 저장하고, 클래스 로더를 통해 Method Area에 클래스 정보를 로드한다. 이후, 변수나 객체는 힙(Heap) 영역에 할당되거나, 스택(Stack) 영역에 저장되어 실행될것인데
이 흔히 일컫는 JVM 메모리 구조인 Runtime Data Area에 대해 뜯어보자.
Runtime Data Area

Runtime Data Area는 위와 같이 5가지 영역으로 이루어져 있다.
- Method Area : 클래스(Byte Code / .class)에 대한 정보가 올라오는 영역. 모든 쓰레드가 공유
- Heap : new 키워드를 통해 생성된 인스턴스가 생성되는 영역. 모든 쓰레드가 공유
- Stack : 지역변수, 매개변수, 리턴값 등 임시적으로 사용되는 값들이 저장되는 영역
- PC Register : 현재 쓰레드가 실행되는 부분의 주소와 명령을 저장하는 영역
- Native Method Stack : Native 언어로 작성된 코드를 실행하기 위한 영역
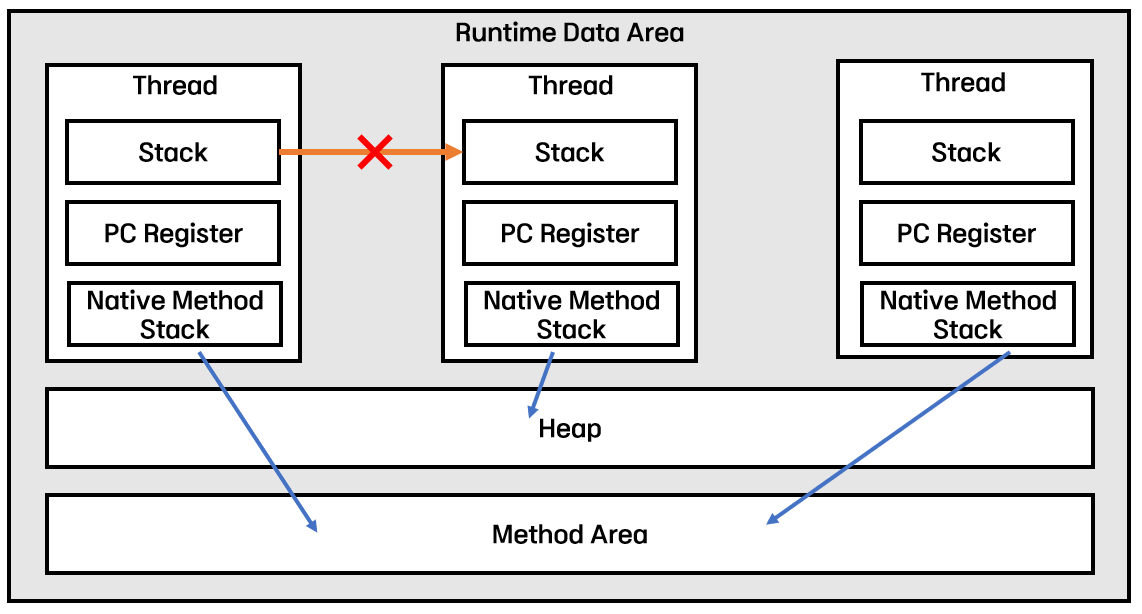
위의 그림처럼 Runtime Data Area의 Stack, PC Register, Native Method Stack은 쓰레드가 생성될 때마다 하나씩 새로 생성되어 쓰레드에 할당되고, Method Area와 Heap은 JVM이 시작될 때 할당되어 모든 쓰레드가 공유한다.
이 때, 각각의 쓰레드는 다른 쓰레드에게 할당된 메모리 영역을 침범할 수 없기 때문에 코드를 작성할 때 지역변수의 동시성 문제를 고려하지 않아도 된다.
Method Area
Static영역으로 클래스에 대한 정보가 올라오는 영역으로 모든 쓰레드가 공유함.
- 클래스의 구조 정보 (Metadata)
: 클래스가 로드될 때 클래스 로더 (ClassLoader) 에 의해 읽혀지고, 해당 클래스의 메타데이터가 Method Area에 저장돼.- 클래스의 이름 (Fully Qualified Name)
- 패키지 정보
- 슈퍼클래스 정보
- 구현한 인터페이스 목록
- 필드 (Field) 정보 (변수 타입, 접근 제어자 등)
- 메서드 (Method) 정보 (이름, 반환 타입, 매개변수 정보 등)
- Static Variables & Static Method
: 인스터를 생성하지 않아도 사용 가능 - Runtime Constant Pool (런타임 상수 풀)
: 클래스 내부에서 사용되는 상수(Constant) 들이 저장되는 영역이야- final 키워드로 선언된 상수
- 문자열 리터럴 (String Pool)
// String Pool(문자열 리터럴)
String s1 = "hi"; // String Pool에 처음 등록
String s2 = "hi"; // String Pool에 이미 존재
System.out.println(s1 == s2); // true
String s3 = new String("hi"); // new 키워드를 사용하면 새로운 객체가 Heap에 생성
System.out.println(s1 == s3); // false
// intern()을 호출하면 Heap에 있는 문자열을 String Pool에 등록하고, 기존에 동일한 문자열이 있으면 그걸 참조
String str4 = new String("Hello").intern();
System.out.println(str1 == str4); // true (String Pool을 참조)
즉, Method Area에는 Class에 대한 모든 정보가 Byte Code의 형태로 로드된다.
Heap
런타임 시 "new 키워드"를 통해 동적으로 생성된 인스턴스 객체가 저장되는 영역으로 모든 쓰레드가 공유하며, Garbage Collection의 대상이 되는 영역이다
Heap에는 프로그램이 실행되면서 동적으로 생성된 인스턴스가 저장되고, 그 Reference(주소값)를 Stack에 저장한다.
즉, Heap영역의 인스턴스에 접근하기 위해서는 Stack에 저장되어있는 Reference를 통해 접근이 가능하다.
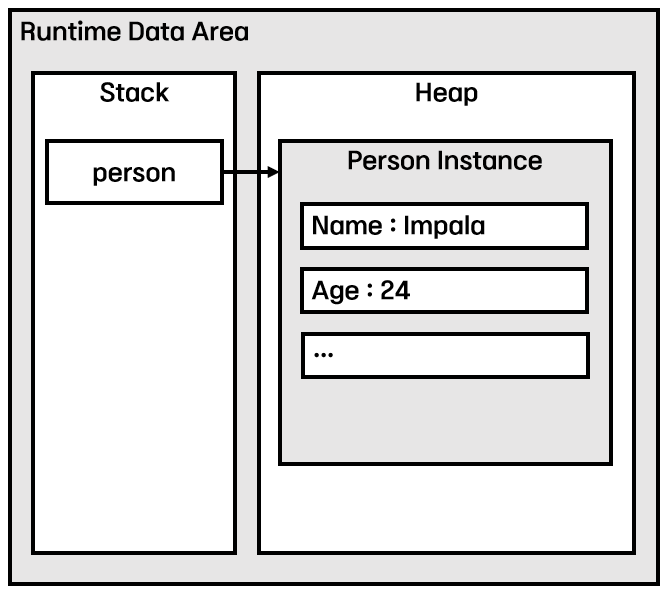
만약 Heap영역이 가득 차게 되면 OutOfMemoryError가 발생한다
또한 JVM은 효율적인 메모리영역의 관리를 위해 Garbage Collection을 수행하는데, Heap 영역이 Garbage Collection의 대상이 된다.

Heap영역은 효율적인 Garbage Collection을 위해 크게 3가지 영역으로 구분된다.
- Young(New) Generation
- new 키워드를 통해 새로운 인스턴스가 생성되면 Eden영역에 저장되고, 이후 Servivor로 이동하게 된다.
- 시간이 지나면서 이 영역에 있는 데이터는 우선순위에 따라 Old영역으로 이동하거나 GC에 의해 회수된다(Minor GC)
- Tenured(Old) Generation
- Young Generation영역에 저장되었던 객체 중 오래된 인스턴스가 이동되어 저장되는 영역.
- Old영역에 할당된 메모리가 허용치를 넘게 되면, Old영역에 있는 모든 인스턴스들을 검사하여 참조되지 않는 인스턴스를 한꺼번에 삭제한다(Major GC)
- Major GC가 발생하면 GC를 실행하는 쓰레드를 제외한 모든 쓰레드가 작업을 중지한다(Stop-the-World)
- Permanent Generation(Metaspace)
- ClassLoader에 의해 동적으로 로딩된 클래스의 메타데이터가 저장되는 영역
- Java 8 이후 Metaspace로 대체되어 Heap영역에서 제외되었다
Stack
지역변수, 메소드의 매개변수, 리턴값 등 임시적으로 사용되는 값들이 저장되는 영역으로 PC Register, Native Method Stack과 함께 쓰레드가 생성될 때마다 할당된다.
프로그램 실행 시 메소드가 실행되면 JVM은 Stack영역에 해당 메소드의 frame을 push하고, 데이터를 임시적으로 저장한다. 메소드가 종료되거나 예외가 터진다면 Stack에서 해당 메소드의 frame을 pop한다.

Stack Frame은 메소드 호출마다 생성되며, 해당 메소드의 실행 동안 필요한 데이터를 저장.
public class Main {
public static void main(String[] args) {
Main main = new Main();
main.methodA(3);
}
private int methodA(int param) {
int localVariable = 1;
int sum = localVariable + param;
methodB();
return sum;
}
private void methodB() {}
}위 코드를 실행시킨다고 가정해보자. 우선 JVM Stack에는 main() → methodA → methodB() 의 프레임이 순서대로 push()될 것이다.
처음에 methodB()는 인자도 없고 연산도 없어서 바로 pop()이 될텐데 그 다음 methodA를 조금더 자세히 보자.
Local Variables Array에서 첫 번째 인덱스인 0 인덱스에서 자기 자신에 대한 참조, 인덱스 1에는 인자인 3, 그 후에 Local Variables에는 선언되는 지역 변수가 순차적으로 쌓일 것이다.

이때 그냥 선언 된다면 바이트 코드에 의해 바로 Local Variables Array에 담기며 만약 연산을 하는 경우 바이트 코드의 명령에 따라 Operand Stack에 연산할 값들을 쌓아놓고 순차적으로 연산을 진행한 후 그 연산 결과를 Operan Stack에서 꺼내어 Local Variables Arrays에 담는 것이다.
- Constant Pool Reference: Method Area의 Runtime Constant Pool에 대한 참조
- 메소드가 실행될 때, Operand Stack에서 연산을 수행하는 도중 필요한 상수 값은 Constant Pool에서 가져온다.
- Local Variables Array : 매소드 내의 지역변수를 담고있는 배열
- 첫번째 인덱스에는 현재 인스턴스에 대한 참조값을 저장(this)
- 두번째 인덱스부터 매개변수 -> 지역변수 순으로 값을 저장
- Operand Stack : 피연산값과 계산과정에서 생기는 중간값을 저장
- 계산을 수행할 때 사용되는 영역입니다. 연산이 필요할 때 피연산자를 Local Variables에서 가져와서 Operand Stack에 놓고, 연산을 한 뒤 결과를 다시 Operand Stack에 저장
- 따라서 연산에 필요한 operand가 모두 Stack에 저장되어있기 때문에 Byte Code는 일반적인 어셈블리어와 달리 operand를 지정하지 않아도 연산이 가능하다
- 다른 어셈블리어와 달리 연산에 레지스터를 쓰지 않은 이유는 각 디바이스마다 레지스터의 수가 달라 그 수를 가정할 수 없기 때문에 하드웨어의 관여를 최소화하기 위해 JVM에서는 연산과정이 복잡하더라도 Stack을 사용한다
만약 쓰레드가 사용할 수 있는 스택의 크기를 넘기게 되면 StackOverflowError 가 발생한다. 또한 스택을 동적으로 확장할 때 확장할 메모리가 부족하거나 새로운 쓰레드 생성 시 스택에 할당할 메모리가 부족하면 OutOfMemoryError 가 발생한다.
PC Register
Stack, Native Method Stack과 함께 쓰레드가 생성될 때 각 쓰레드마다 할당되는 영역
PC Register는 JVM의 각 쓰레드마다 하나씩 존재하는 레지스터입니다.
이 레지스터는 현재 실행 중인 명령어의 주소를 저장합니다.
다시 말해, PC Register는 프로그램 실행 흐름을 추적하는 데 사용
Native Method Stack
Native 언어(C/C++, 어셈블리)로 작성된 코드를 실행하기 위한 스택 메모리 영역
Native Method Stack은 Java 이외의 언어(예: C, C++, 어셈블리 등)로 작성된 네이티브 코드를 실행하기 위한 JVM 메모리 영역으로 JNI(Java Native Interface)를 통해 호출되는 C/C++ 등의 코드를 수행하기 위한 스택이다.
// 자바 코드
public class NativeExample {
// 네이티브 메서드 선언 (C에서 구현)
public native void sayHello();
// 라이브러리 로드 (컴파일된 C 코드)
static {
System.loadLibrary("nativeLib"); // nativeLib.so (Linux) 또는 nativeLib.dll (Windows)
}
public static void main(String[] args) {
new NativeExample().sayHello(); // C의 함수가 실행됨
}
}
// C 코드
#include <jni.h>
#include <stdio.h>
#include "NativeExample.h" // Java 클래스의 헤더 파일
// 네이티브 메서드 구현 (Java에서 호출됨)
JNIEXPORT void JNICALL Java_NativeExample_sayHello(JNIEnv *env, jobject obj) {
printf("Hello from C!\n"); // C에서 출력
}
Java 코드가 컴파일 및 인터프리팅 되는 과정은 꽤나 이해했지만 사실 메모리 구조 하나하나에 대해 깊게 이해하지 못해 외우지는 못할 것같다. 그렇지만 이전에 JVM에 대해 공부했을때보다 훨씬 내용이 깊어진 것 같다. 몇 개월 뒤에 다시 보면 또 받아들일 수 있는 깊이가 다를 것 같다.
'Back-End > Java' 카테고리의 다른 글
| [Algorithm] Segment Tree(세그먼트 트리) (0) | 2025.02.07 |
|---|---|
| [Java] 다익스트로 알고리즘 & 플로이드 와샬 알고리즘 (0) | 2024.11.14 |
| [Java] JVM 메모리 구조(Method-Static, Heap, Stack) (2) | 2024.11.06 |
| [Java] HashMap 시간복잡도 (0) | 2024.10.31 |
| [Java] 자바 코테를 위한 정렬(Sorting) 및 Comparable와 Comparator (0) | 2024.10.24 |


